เริ่มจากครั้งแรกที่เข้าเรียนก็ได้นั่งเรียนกับเพื่อนที่มาจากศูนย์อื่นทำให้ได้รู้จักเพื่อนมากขึ้น และการเข้าเรียนแต่ละครั้งเราก็ต้องเข้าแถวให้เป็นระเบียบและต้องทำเวลาทำให้เราต้องปรับตัวเองให้มีระเบียบให้ตรงต่อเวลา และการทำงานร่วมกันไม่ว่าจะเป็นโครงการที่ทำกันเป็นกลุ่มเราก็ต้องทำกันเป็นทีมและงานแขนงที่เราต้องทำงานร่วมกับเด็กห้องอื่นศูนย์อื่นทำให้รู้จักฝึกการทำงานร่วมกับคนอื่น เราต้องมีการประสานงานกันแต่ละห้องและมีการแบ่งหน้าที่ที่ตัวเองต้องรับผิดชอบกัน และสัปดาห์ที่อาจารย์สอนเรื่องมารู้จักสวนดุสิตกันเถอะทำให้เราได้รู้เกี่ยวกับประวัติสวนดุสิตที่เราไม่เคยรู้ว่าสวนดุสิตมีความเป็นมายังไง และวันที่เป็นปัจฉิมนิเทศก็ได้ข้อคิดที่พระอาจารย์ท่านได้เตือนสติเราให้เราเป็นคนดีเมื่อเราเจออุปสรรคใดๆก็ตามเราก็ต้องมีสติใช้สติแก้ปัญหาที่เกิดขึ้น เหมือนกับแมงกุดจี่ที่ทางเดินของมันมีทั้งราบเรียบและขรุขระแต่มันก็สามารถที่จะผ่านพ้นไปได้และเมื่อเจอกับทางตันมันก็ใช้วิธีของมันแก้ปัญหาโดยไม่ย่อท้อต่ออุปสรรค
สิ่งที่ได้รับคือ
- การปรับตัวให้เป็นคนตรงต่อเวลา
- ฝึกความมีระเบียบ
- การทำงานกันเป็นทีม การทำงงานร่วมกับคนอื่น
- การมีความรับผิดชอบในหน้าที่ของตัวเองที่ได้รับมอบหมายจากเพื่อน
- จากการที่ได้ฟังพระอาจารย์ได้มาบรรยายก็ได้ข้อคิดว่าคนเราเมื่อมีปัญหาอะไรนั้นเราต้องมีสติใช้สติแก้ปัญหาทุกอย่าง
และการไม่ย่อท้อต่ออุปสรรคต่างๆ
วันพฤหัสบดีที่ 15 ตุลาคม พ.ศ. 2552
วันอังคารที่ 22 กันยายน พ.ศ. 2552
DTS 11-16/09/52
Summary B4 Final
ทรี (Tree)
เป็นโครงสร้างข้อมูลที่ความสัมพันธ์
ระหว่าง โหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับ
ชั้น (Hierarchical Relationship)เช่น แผนผังองค์ประกอบของหน่วยงานต่าง ๆ
โครงสร้างสารบัญหนังสือ เป็นต้น
การท่องไปในไบนารีทรี
วิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบ
แผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง
วิธีการท่องไปในทรีรี 6 วิธี คือ NLR LNR LRN NRL RNL และ RLN
แต่วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรก
เท่านั้นคือ NLR LNR และ LRN ซึ่งลักษณะการนิยามเป็นนิยามแบบ รีเคอร์ซีฟ(Recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. การท่องไปแบบพรีออร์เดอร์
(Preorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี
NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
2.การท่องไปแบบอินออร์เดอร์
(Inorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LNR
มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
3. การท่องไปแบบโพสออร์เดอร์
(Postorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LRN มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสต์ออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสต์ออร์เดอร์
(3) เยือนโหนดราก
ไบนารีเซิร์ชทรี
ไบนารีเซิร์ชทรี (Binary Search Tree)
เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนด
ในทรี ค่าของโหนดรากมีค่ามากกว่าค่าของทุก
โหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่า
หรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวา
และในแต่ละทรีย่อยก็มี คุณสมบัติเช่นเดียวกัน
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา
อาจจะใช้วิธีแอดจาเซนซีลิสต์
(Adjacency List) ซึ่งเป็นวิธีที่คล้ายวิธี
จัดเก็บกราฟด้วยการเก็บโหนดและพอยน์
เตอร์ แต่ต่างกันตรงที่ จะใช้ ลิงค์ลิสต์แทน
เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ
1. การค้นหาแบบกว้าง (Breadth-first Search)
2. การค้นหาแบบลึก (Depth-first Search)
กราฟ มีน้ำหนัก หมายถึง กราฟที่ทุก
เอดจ์ มีค่าน้ำหนักกำกับ ซึ่งค่าน้ำหนักอาจสื่อถึง
ระยะทาง เวลา ค่าใช้จ่าย เป็นต้น นิยมนำไปใช้
แก้ปัญหาหลัก ๆ 2 ปัญหา คือ
1. การสร้างต้นไม้ทอดข้ามน้อยที่สุด
(Minimum Spanning Trees :MST)
2. การหาเส้นทางที่สั้นที่สุด(Shortest path)
Sorting
การเรียงลำดับแบบเร็ว (quick sort)
เป็นวิธีการเรียงลำดับที่ใช้เวลาน้อยเหมาะสำหรับข้อมูลที่มีจำนวนมากที่ต้องการความรวดเร็ว
ในการทำงาน วิธีนี้จะเลือกข้อมูลจากกลุ่มข้อมูลขึ้นมาหนึ่งค่าเป็นค่าหลัก แล้วหาตำแหน่งที่ถูกต้อง
ให้กับค่าหลักนี้ เมื่อได้ตำแหน่งที่ถูกต้องแล้ว ใช้ค่าหลักนี้เป็นหลักในการแบ่งข้อมูลออกเป็นสองส่วน
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก ส่วนแรกอยู่ในตอนหน้าข้อมูล ทั้งหมดจะมีค่าน้อยกว่าค่าหลักที่เป็นตัวแบ่งส่วน
อีกส่วนหนึ่งจะอยู่ในตำแหน่งตอนหลังข้อมูลทั้งหมด จะมีค่ามากกว่าค่าหลัก แล้วนำแต่ละ
ส่วนย่อยไปแบ่งย่อยในลักษณะเดียวกันต่อไปจนกระทั่งแต่ละส่วนไม่สามารถแบ่งย่อยได้อีก
ต่อไปจะได้ข้อมูลที่มีการเรียงลำดับตามที่ต้องการถ้าเป็นการเรียงลำดับจากน้อยไปมากการเปรียบเทียบเพื่อหาตำแหน่งให้กับค่าหลัก
ตัวแรกเริ่มจากข้อมูลในตำแหน่งแรกหรือสุดท้ายก็ได้ถ้าเริ่มจากข้อมูลที่ตำแหน่งที่ 1 เป็นค่าหลัก พิจารณา
เปรียบเทียบค่าหลักกับข้อมูลในตำแหน่งสุดท้ายถ้าค่าหลักมีค่าน้อยกว่าให้เปรียบเทียบกับข้อมูลในตำแหน่งรอง
สุดท้ายไปเรื่อย ๆ จนกว่าจะพบค่าที่น้อยกว่าค่าหลัก แล้วให้สลับตำแหน่งกัน
หลังจากสลับตำแหน่งแล้วนำค่าหลักมาเปรียบเทียบกับข้อมูล ในตำแหน่งที่ 2, 3,
ไปเรื่อย ๆ จนกว่าจะพบค่าที่มากกว่าค่าหลักสลับตำแหน่งเมื่อเจอข้อมูลที่มากกว่าค่าหลัก ทำ
เช่นนี้ไปเรื่อย ๆ จนกระทั่งได้ตำแหน่งที่ถูกต้องของค่าหลักนั้น ก็จะแบ่งกลุ่มข้อมูลออกเป็นสอง
ส่วน ส่วนแรกข้อมูลทั้งหมดมีค่าน้อยกว่าค่าหลักและส่วนที่สองข้อมูลทั้งหมดมีค่ามากกว่าค่าหลัก
การค้นหาข้อมูล (Searching)
การค้นหา คือการใช้วิธีการค้นหากับโครงสร้างข้อมูล เพื่อดูว่าข้อมูลตัวที่
ต้องการถูกเก็บอยู่ในโครงสร้างแล้วหรือยัง การค้นหาข้อมูลทำเพื่อดูรายละเอียดเฉพาะข้อมูลส่วนที่ต้องการ ดึงข้อมูลที่ค้นหาออกจากโครงสร้าง เปลี่ยนแปลงแก้ไขรายละเอียดข้อมูลตัวที่ค้นพบ หรือเพิ่มข้อมูลตัวที่ค้นพบแล้วพบว่ายังไม่เคยเก็บไว้ในโครงสร้างเลยเข้าไปเก็บไว้ในโครงต่อไป
วิธีการค้นหาข้อมูล
1. การค้นหาแบบเชิงเส้นหรือการค้นหาตามลำดับ(Linear)เป็นวิธีที่ใช้กับข้อมูลที่ยังไม่ได้เรียงลำดับ
หลักการ คือ ให้นำข้อมูลที่จะหามาเปรียบเทียบกับข้อมูลตัว
แรกในแถวลำดับ
ถ้าไม่เท่ากันให้เปรียบเทียบกับข้อมูลตัวถัดไป
ถ้าเท่ากันให้หยุดการค้นหา หรือการค้นหาจะหยุดเมื่อพบ
ข้อมูลที่ต้องการหรือหาข้อมูลทุกจำนวนในแถวลำดับแล้วไม่พบ
2. การค้นหาแบบเซนทินัล (Sentinel)เป็นวิธีที่การค้นหาแบบเดียวกับวิธีการค้นหาแบบเชิงเส้น
แต่ประสิทธิภาพดีกว่าตรงที่เปรียบเทียบน้อยครั้งกว่า พัฒนามาจากอัลกอริทึมแบบเชิงเส้น
หลักการ1) เพิ่มขนาดของแถวลำดับ ที่ใช้เก็บข้อมูลอีก 1 ที่
2) นำข้อมูลที่จะใช้ค้นหาข้อมูลใน Array ไปฝากที่ต้นหรือ ท้าย
Array
3) ตรวจสอบผลลัพธ์จากการหา
โดยตรวจสอบจากตำแหน่งที่พบ ถ้าตำแหน่งที่พบมีค่าเท่ากับ n-1
แสดงว่าหาไม่พบ นอกนั้นถือว่าพบข้อมูลที่ค้าหา
3. การค้นหาแบบไบนารี (Binary Search)
การค้นหาแบบไบนารีใช้กับข้อมูลที่ ถูกจัดเรียงแล้วเท่านั้น
หลักการของการค้นหาคือ ข้อมูลถูกแบ่งออกเป็นสองส่วน
แล้วนำค่ากลางข้อมูลมาเปรียบเทียบกับคีย์ที่ต้องการหา
1.หาตัวแทนข้อมูลเพื่อนำมาเปรียบเทียบกับค่าที่ต้องการค้น
ตำแหน่งตัวแทนข้อมูลหาได้จากสูตร
mid = (low+high)/2
mid คือ ตำแหน่งกลาง ,low คือ ตำแหน่งต้นแถวลำดับ
high คือ ตำแหน่งท้ายของแถวลำดับ
2.นำผลการเปรียบเทียบกรณีที่หาไม่พบมาใช้ในการค้นหารอบต่อไป
ทรี (Tree)
เป็นโครงสร้างข้อมูลที่ความสัมพันธ์
ระหว่าง โหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับ
ชั้น (Hierarchical Relationship)เช่น แผนผังองค์ประกอบของหน่วยงานต่าง ๆ
โครงสร้างสารบัญหนังสือ เป็นต้น
การท่องไปในไบนารีทรี
วิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบ
แผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง
วิธีการท่องไปในทรีรี 6 วิธี คือ NLR LNR LRN NRL RNL และ RLN
แต่วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรก
เท่านั้นคือ NLR LNR และ LRN ซึ่งลักษณะการนิยามเป็นนิยามแบบ รีเคอร์ซีฟ(Recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. การท่องไปแบบพรีออร์เดอร์
(Preorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี
NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
2.การท่องไปแบบอินออร์เดอร์
(Inorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LNR
มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
3. การท่องไปแบบโพสออร์เดอร์
(Postorder Traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ
ในทรีด้วยวิธี LRN มีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสต์ออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสต์ออร์เดอร์
(3) เยือนโหนดราก
ไบนารีเซิร์ชทรี
ไบนารีเซิร์ชทรี (Binary Search Tree)
เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนด
ในทรี ค่าของโหนดรากมีค่ามากกว่าค่าของทุก
โหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่า
หรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวา
และในแต่ละทรีย่อยก็มี คุณสมบัติเช่นเดียวกัน
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา
อาจจะใช้วิธีแอดจาเซนซีลิสต์
(Adjacency List) ซึ่งเป็นวิธีที่คล้ายวิธี
จัดเก็บกราฟด้วยการเก็บโหนดและพอยน์
เตอร์ แต่ต่างกันตรงที่ จะใช้ ลิงค์ลิสต์แทน
เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ
1. การค้นหาแบบกว้าง (Breadth-first Search)
2. การค้นหาแบบลึก (Depth-first Search)
กราฟ มีน้ำหนัก หมายถึง กราฟที่ทุก
เอดจ์ มีค่าน้ำหนักกำกับ ซึ่งค่าน้ำหนักอาจสื่อถึง
ระยะทาง เวลา ค่าใช้จ่าย เป็นต้น นิยมนำไปใช้
แก้ปัญหาหลัก ๆ 2 ปัญหา คือ
1. การสร้างต้นไม้ทอดข้ามน้อยที่สุด
(Minimum Spanning Trees :MST)
2. การหาเส้นทางที่สั้นที่สุด(Shortest path)
Sorting
การเรียงลำดับแบบเร็ว (quick sort)
เป็นวิธีการเรียงลำดับที่ใช้เวลาน้อยเหมาะสำหรับข้อมูลที่มีจำนวนมากที่ต้องการความรวดเร็ว
ในการทำงาน วิธีนี้จะเลือกข้อมูลจากกลุ่มข้อมูลขึ้นมาหนึ่งค่าเป็นค่าหลัก แล้วหาตำแหน่งที่ถูกต้อง
ให้กับค่าหลักนี้ เมื่อได้ตำแหน่งที่ถูกต้องแล้ว ใช้ค่าหลักนี้เป็นหลักในการแบ่งข้อมูลออกเป็นสองส่วน
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก ส่วนแรกอยู่ในตอนหน้าข้อมูล ทั้งหมดจะมีค่าน้อยกว่าค่าหลักที่เป็นตัวแบ่งส่วน
อีกส่วนหนึ่งจะอยู่ในตำแหน่งตอนหลังข้อมูลทั้งหมด จะมีค่ามากกว่าค่าหลัก แล้วนำแต่ละ
ส่วนย่อยไปแบ่งย่อยในลักษณะเดียวกันต่อไปจนกระทั่งแต่ละส่วนไม่สามารถแบ่งย่อยได้อีก
ต่อไปจะได้ข้อมูลที่มีการเรียงลำดับตามที่ต้องการถ้าเป็นการเรียงลำดับจากน้อยไปมากการเปรียบเทียบเพื่อหาตำแหน่งให้กับค่าหลัก
ตัวแรกเริ่มจากข้อมูลในตำแหน่งแรกหรือสุดท้ายก็ได้ถ้าเริ่มจากข้อมูลที่ตำแหน่งที่ 1 เป็นค่าหลัก พิจารณา
เปรียบเทียบค่าหลักกับข้อมูลในตำแหน่งสุดท้ายถ้าค่าหลักมีค่าน้อยกว่าให้เปรียบเทียบกับข้อมูลในตำแหน่งรอง
สุดท้ายไปเรื่อย ๆ จนกว่าจะพบค่าที่น้อยกว่าค่าหลัก แล้วให้สลับตำแหน่งกัน
หลังจากสลับตำแหน่งแล้วนำค่าหลักมาเปรียบเทียบกับข้อมูล ในตำแหน่งที่ 2, 3,
ไปเรื่อย ๆ จนกว่าจะพบค่าที่มากกว่าค่าหลักสลับตำแหน่งเมื่อเจอข้อมูลที่มากกว่าค่าหลัก ทำ
เช่นนี้ไปเรื่อย ๆ จนกระทั่งได้ตำแหน่งที่ถูกต้องของค่าหลักนั้น ก็จะแบ่งกลุ่มข้อมูลออกเป็นสอง
ส่วน ส่วนแรกข้อมูลทั้งหมดมีค่าน้อยกว่าค่าหลักและส่วนที่สองข้อมูลทั้งหมดมีค่ามากกว่าค่าหลัก
การค้นหาข้อมูล (Searching)
การค้นหา คือการใช้วิธีการค้นหากับโครงสร้างข้อมูล เพื่อดูว่าข้อมูลตัวที่
ต้องการถูกเก็บอยู่ในโครงสร้างแล้วหรือยัง การค้นหาข้อมูลทำเพื่อดูรายละเอียดเฉพาะข้อมูลส่วนที่ต้องการ ดึงข้อมูลที่ค้นหาออกจากโครงสร้าง เปลี่ยนแปลงแก้ไขรายละเอียดข้อมูลตัวที่ค้นพบ หรือเพิ่มข้อมูลตัวที่ค้นพบแล้วพบว่ายังไม่เคยเก็บไว้ในโครงสร้างเลยเข้าไปเก็บไว้ในโครงต่อไป
วิธีการค้นหาข้อมูล
1. การค้นหาแบบเชิงเส้นหรือการค้นหาตามลำดับ(Linear)เป็นวิธีที่ใช้กับข้อมูลที่ยังไม่ได้เรียงลำดับ
หลักการ คือ ให้นำข้อมูลที่จะหามาเปรียบเทียบกับข้อมูลตัว
แรกในแถวลำดับ
ถ้าไม่เท่ากันให้เปรียบเทียบกับข้อมูลตัวถัดไป
ถ้าเท่ากันให้หยุดการค้นหา หรือการค้นหาจะหยุดเมื่อพบ
ข้อมูลที่ต้องการหรือหาข้อมูลทุกจำนวนในแถวลำดับแล้วไม่พบ
2. การค้นหาแบบเซนทินัล (Sentinel)เป็นวิธีที่การค้นหาแบบเดียวกับวิธีการค้นหาแบบเชิงเส้น
แต่ประสิทธิภาพดีกว่าตรงที่เปรียบเทียบน้อยครั้งกว่า พัฒนามาจากอัลกอริทึมแบบเชิงเส้น
หลักการ1) เพิ่มขนาดของแถวลำดับ ที่ใช้เก็บข้อมูลอีก 1 ที่
2) นำข้อมูลที่จะใช้ค้นหาข้อมูลใน Array ไปฝากที่ต้นหรือ ท้าย
Array
3) ตรวจสอบผลลัพธ์จากการหา
โดยตรวจสอบจากตำแหน่งที่พบ ถ้าตำแหน่งที่พบมีค่าเท่ากับ n-1
แสดงว่าหาไม่พบ นอกนั้นถือว่าพบข้อมูลที่ค้าหา
3. การค้นหาแบบไบนารี (Binary Search)
การค้นหาแบบไบนารีใช้กับข้อมูลที่ ถูกจัดเรียงแล้วเท่านั้น
หลักการของการค้นหาคือ ข้อมูลถูกแบ่งออกเป็นสองส่วน
แล้วนำค่ากลางข้อมูลมาเปรียบเทียบกับคีย์ที่ต้องการหา
1.หาตัวแทนข้อมูลเพื่อนำมาเปรียบเทียบกับค่าที่ต้องการค้น
ตำแหน่งตัวแทนข้อมูลหาได้จากสูตร
mid = (low+high)/2
mid คือ ตำแหน่งกลาง ,low คือ ตำแหน่งต้นแถวลำดับ
high คือ ตำแหน่งท้ายของแถวลำดับ
2.นำผลการเปรียบเทียบกรณีที่หาไม่พบมาใช้ในการค้นหารอบต่อไป
วันจันทร์ที่ 21 กันยายน พ.ศ. 2552
DTS 10-09/09/52
สรุปบทเรียน การเรียงลำดับ
การเรียงลำดับข้อมูลเป็นเรื่องสำคัญมากเรื่องหนึ่งเนื่องจากทำให้ผู้ต้องการใช้ข้อมุลเช่น ผู้บริหาร,ผู้ปฏิบัติงาน (พนักงาน) สามารถทำความเข้าใจกับข้อมูลหรือทำการค้นหาข้อมูลได้ง่ายและเร็วยิ่งขึ้นตามที่ต้องการ
การเรียงลำดับที่ดี และเหมาะสมกับระบบงาน เพื่อให้ประสิทธิภาพในการ
ทำงานสูงสุด ควรจะต้องคำนึงถึงสิ่งต่าง ๆ ดังต่อไปนี้
(1) เวลาและแรงงานที่ต้องใช้ในการเขียนโปรแกรม
(2) เวลาที่เครื่องคอมพิวเตอร์ต้องใช้ในการทำงานตามโปรแกรมที่เขียน
(3) จำนวนเนื้อที่ในหน่วยความจำหลักมีเพียงพอหรือไม่
วิธีการเรียงลำดับ
วิธีการเรียงลำดับสามารถแบ่งออกเป็น2 ประเภท คือ
(1)การเรียงลำดับแบบภายใน (internal sorting)เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ใน
หน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะคำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อนข้อมูลภายในความจำหลัก
(2) การเรียงลำดับแบบภายนอก
(external sorting) เป็นการเรียงลำดับข้อมูลที่
เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการ
เรียงลำดับข้อมูลในแฟ้มข้อมูล (file) เวลาที่ใช้ใน
การเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่าง
การถ่ายเทข้อมูลจากหน่วยความจำหลักและ
หน่วยความจำสำรองนอกเหนือจากเวลาที่ใช้
ในการเรียงลำดับข้อมูลแบบภายใน
การเรียงลำดับแบบเลือก (selection sort)ทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ ข้อมูลนั้นควรจะอยู่ทีละ
ตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
1. ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บ
ไว้ที่ตำแหน่งที่ 1
2. ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่
ตำแหน่งที่สอง
3. ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกค่า
ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการ
การจัดเรียงลำดับแบบเลือกเป็นวิธีที่ง่ายและ
ตรงไปตรงมา แต่มีข้อเสียตรงที่ใช้เวลาในการจัดเรียงนาน
เพราะแต่ละรอบต้องเปรียบเทียบกับข้อมูลทุกตัว ถ้ามี
จำนวนข้อมูลทั้งหมด n ตัว ต้องทำการเปรียบเทียบทั้งหมด
n – 1 รอบ และจำนวนครั้งของการเปรียบเทียบในแต่ละ
รอบเป็นดังนี้
รอบที่ 1 เปรียบเทียบเท่ากับ n −1 ครั้ง
รอบที่ 2 เปรียบเทียบเท่ากับ n – 2 ครั้ง
...
รอบที่ n – 1 เปรียบเทียบเท่ากับ 1 ครั้ง
การเรียงลำดับแบบฟอง (Bubble Sort)
เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลใน
ตำแหน่งที่อยู่ติดกัน
1. ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่ง
ที่อยู่กัน
2. ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มี
ค่าน้อยกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้า
เป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มี
ค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อย
ในวิธีแบบ Bubble Sort ค่าในการเปรียบเทียบที่น้อยที่สุดหรือมากที่สุด จะลอยขึ้นข้างบน เหมือนกับฟองอากาศ
การเรียงลำดับอย่างเร็ว (quick sort)จะแบ่งข้อมูลเป็นสองกลุ่ม โดยใน การจัดเรียงจะเลือกข้อมุลตัวใดตัวหนึ่งออกมา ซึ่งจะเป็นตัวที่แบ่งข้อมูลออกเป็นสองกลุ่ม โดยกลุ่มแรกจะต้องมีข้อมูลน้อยกว่า ตัวแบ่ง และกลุ่มที่มีข้อมูลน้อยกว่าตัวแบ่ง และอีกกลุ่มจะมีข้อมูลที่มากกว่าตัวแบ่ง ซึ่งเราเรียกตัวแบ่งว่า ตัวหลัก(pivot) ในการเลือกตัวหลักจะมีอิสระในการเลือกข้อมูลตัวใดก็ได้ที่เราต้องการ การเรียงลำดับแบบเร็วเหมาะกับข้อมูลที่มีการเรียกซ้ำ
การเรียงลำดับแบบแทรก (insertion sort)เป็นการเรียงลำดับที่เพิ่มสมาชิกใหม่เข้าไปในเซ็ต ที่มีการเรียงลำดับข้อมูลอยู่แล้ว แล้วทำให้เซ็ตใหม่มีการเรียงลำดับด้วย
1. เริ่มเปรียบเทียบข้อมูลตำแหน่งที่ 1 และ 2 หรือข้อมูลตำแหน่งสุดท้ายกับรองสุดท้าย
2. ถ้าเป็นการเรียงข้อมูลจากค่าน้อยไปมาก จัดเรียงข้อมูลที่มีค่าน้อยอยู่ก่อนข้อมูลที่มีค่ามาก ถ้าเป็นการเรียงข้อมูลจากมากไปน้อย จัดเรียงข้อมูลที่มีค่ามากอยู่ก่อนข้อมูลที่มีค่าน้อย
ป็นการเรียงลำดับโดยการพิจารณาข้อมูลทีละ
หลัก
1. เริ่มพิจารณาจากหลักที่มีค่าน้อยที่สุดก่อน นั่นคือถ้า
ข้อมูลเป็นเลขจำนวนเต็มจะพิจารณาหลักหน่วยก่อน
2. การจัดเรียงจะนำข้อมูลเข้ามาทีละตัว แล้วนำไป
เก็บไว้ที่ซึ่งจัดไว้สำหรับค่านั้น เป็นกลุ่ม ๆ
ตามลำดับการเข้ามา
3. ในแต่ละรอบเมื่อจัดกลุ่มเรียบร้อยแล้ว ให้
รวบรวมข้อมูลจากทุกกลุ่มเข้าด้วยกัน โดยเริ่มเรียง
จากกลุ่มที่มีค่าน้อยที่สุดก่อนแล้วเรียงไปเรื่อย ๆ จน
หมดทุกกลุ่ม
4. ในรอบต่อไปนำข้อมูลทั้งหมดที่ได้จัดเรียงในหลัก
หน่วยเรียบร้อยแล้วมาพิจารณาจัดเรียงในหลักสิบ
ต่อไป ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกหลักจะ
ได้ข้อมูลที่เรียงลำดับจากน้อยไปมากตามต้องการ
การเรียงลำดับข้อมูลเป็นเรื่องสำคัญมากเรื่องหนึ่งเนื่องจากทำให้ผู้ต้องการใช้ข้อมุลเช่น ผู้บริหาร,ผู้ปฏิบัติงาน (พนักงาน) สามารถทำความเข้าใจกับข้อมูลหรือทำการค้นหาข้อมูลได้ง่ายและเร็วยิ่งขึ้นตามที่ต้องการ
การเรียงลำดับที่ดี และเหมาะสมกับระบบงาน เพื่อให้ประสิทธิภาพในการ
ทำงานสูงสุด ควรจะต้องคำนึงถึงสิ่งต่าง ๆ ดังต่อไปนี้
(1) เวลาและแรงงานที่ต้องใช้ในการเขียนโปรแกรม
(2) เวลาที่เครื่องคอมพิวเตอร์ต้องใช้ในการทำงานตามโปรแกรมที่เขียน
(3) จำนวนเนื้อที่ในหน่วยความจำหลักมีเพียงพอหรือไม่
วิธีการเรียงลำดับ
วิธีการเรียงลำดับสามารถแบ่งออกเป็น2 ประเภท คือ
(1)การเรียงลำดับแบบภายใน (internal sorting)เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ใน
หน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะคำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อนข้อมูลภายในความจำหลัก
(2) การเรียงลำดับแบบภายนอก
(external sorting) เป็นการเรียงลำดับข้อมูลที่
เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการ
เรียงลำดับข้อมูลในแฟ้มข้อมูล (file) เวลาที่ใช้ใน
การเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่าง
การถ่ายเทข้อมูลจากหน่วยความจำหลักและ
หน่วยความจำสำรองนอกเหนือจากเวลาที่ใช้
ในการเรียงลำดับข้อมูลแบบภายใน
การเรียงลำดับแบบเลือก (selection sort)ทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ ข้อมูลนั้นควรจะอยู่ทีละ
ตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ
ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
1. ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บ
ไว้ที่ตำแหน่งที่ 1
2. ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่
ตำแหน่งที่สอง
3. ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกค่า
ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการ
การจัดเรียงลำดับแบบเลือกเป็นวิธีที่ง่ายและ
ตรงไปตรงมา แต่มีข้อเสียตรงที่ใช้เวลาในการจัดเรียงนาน
เพราะแต่ละรอบต้องเปรียบเทียบกับข้อมูลทุกตัว ถ้ามี
จำนวนข้อมูลทั้งหมด n ตัว ต้องทำการเปรียบเทียบทั้งหมด
n – 1 รอบ และจำนวนครั้งของการเปรียบเทียบในแต่ละ
รอบเป็นดังนี้
รอบที่ 1 เปรียบเทียบเท่ากับ n −1 ครั้ง
รอบที่ 2 เปรียบเทียบเท่ากับ n – 2 ครั้ง
...
รอบที่ n – 1 เปรียบเทียบเท่ากับ 1 ครั้ง
การเรียงลำดับแบบฟอง (Bubble Sort)
เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลใน
ตำแหน่งที่อยู่ติดกัน
1. ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่ง
ที่อยู่กัน
2. ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มี
ค่าน้อยกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้า
เป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มี
ค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อย
ในวิธีแบบ Bubble Sort ค่าในการเปรียบเทียบที่น้อยที่สุดหรือมากที่สุด จะลอยขึ้นข้างบน เหมือนกับฟองอากาศ
การเรียงลำดับอย่างเร็ว (quick sort)จะแบ่งข้อมูลเป็นสองกลุ่ม โดยใน การจัดเรียงจะเลือกข้อมุลตัวใดตัวหนึ่งออกมา ซึ่งจะเป็นตัวที่แบ่งข้อมูลออกเป็นสองกลุ่ม โดยกลุ่มแรกจะต้องมีข้อมูลน้อยกว่า ตัวแบ่ง และกลุ่มที่มีข้อมูลน้อยกว่าตัวแบ่ง และอีกกลุ่มจะมีข้อมูลที่มากกว่าตัวแบ่ง ซึ่งเราเรียกตัวแบ่งว่า ตัวหลัก(pivot) ในการเลือกตัวหลักจะมีอิสระในการเลือกข้อมูลตัวใดก็ได้ที่เราต้องการ การเรียงลำดับแบบเร็วเหมาะกับข้อมูลที่มีการเรียกซ้ำ
การเรียงลำดับแบบแทรก (insertion sort)เป็นการเรียงลำดับที่เพิ่มสมาชิกใหม่เข้าไปในเซ็ต ที่มีการเรียงลำดับข้อมูลอยู่แล้ว แล้วทำให้เซ็ตใหม่มีการเรียงลำดับด้วย
1. เริ่มเปรียบเทียบข้อมูลตำแหน่งที่ 1 และ 2 หรือข้อมูลตำแหน่งสุดท้ายกับรองสุดท้าย
2. ถ้าเป็นการเรียงข้อมูลจากค่าน้อยไปมาก จัดเรียงข้อมูลที่มีค่าน้อยอยู่ก่อนข้อมูลที่มีค่ามาก ถ้าเป็นการเรียงข้อมูลจากมากไปน้อย จัดเรียงข้อมูลที่มีค่ามากอยู่ก่อนข้อมูลที่มีค่าน้อย
ป็นการเรียงลำดับโดยการพิจารณาข้อมูลทีละ
หลัก
1. เริ่มพิจารณาจากหลักที่มีค่าน้อยที่สุดก่อน นั่นคือถ้า
ข้อมูลเป็นเลขจำนวนเต็มจะพิจารณาหลักหน่วยก่อน
2. การจัดเรียงจะนำข้อมูลเข้ามาทีละตัว แล้วนำไป
เก็บไว้ที่ซึ่งจัดไว้สำหรับค่านั้น เป็นกลุ่ม ๆ
ตามลำดับการเข้ามา
3. ในแต่ละรอบเมื่อจัดกลุ่มเรียบร้อยแล้ว ให้
รวบรวมข้อมูลจากทุกกลุ่มเข้าด้วยกัน โดยเริ่มเรียง
จากกลุ่มที่มีค่าน้อยที่สุดก่อนแล้วเรียงไปเรื่อย ๆ จน
หมดทุกกลุ่ม
4. ในรอบต่อไปนำข้อมูลทั้งหมดที่ได้จัดเรียงในหลัก
หน่วยเรียบร้อยแล้วมาพิจารณาจัดเรียงในหลักสิบ
ต่อไป ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกหลักจะ
ได้ข้อมูลที่เรียงลำดับจากน้อยไปมากตามต้องการ
DTS 09-02/09/52
สรุปบทเรียนเรื่อง Graph
กราฟ (Graph) เป็นโครงสร้างข้อมูลไม่เป็นเชิงเส้น (Nonlinear Data Structure) มีความแตกต่างจากโครงสร้างข้อมูลทรีในบทที่ผ่านมา กราฟเป็นโครงสร้างข้อมูลที่มีการนำไปใช้ในงานที่เกี่ยวข้องกับการแก้ปัญหาที่ค่อนข้างซับซ้อนเช่น การวางข่าย งานคอมพิวเตอร์ การวิเคราะห์เส้นทางวิกฤติ และปัญหาเส้นทางที่สั้นที่สุด เป็นต้น
กราฟ เป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้นที่ประกอบด้วยกลุ่มของสิ่งสองสิ่งคือ
(1) โหนด (nodes) หรือ เวอร์เทกซ์ (vertexes)
(2) เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (edges)
การเขียนกราฟแสดงโหนดและเส้นเชื่อมความสัมพันธ์ระหว่างโหนดไม่มีรูปแบบที่ตายตัว การลากเส้นความสัมพันธ์เป็นเส้นลักษณะไหนก็ได้ที่สามารถแสดง ความสัมพันธ์ระหว่างโหนดได้ถูกต้อง
กราฟที่มีเอ็จเชื่อมระหว่างโหนดสองโหนดถ้าเอ็จไม่มีลำดับ ความสัมพันธ์จะเรียกกราฟนั้นว่า
กราฟแบบไม่มีทิศทาง (Undirected Graphs)
และถ้ากราฟนั้นมีเอ็จที่มีลำดับความสัมพันธ์หรือมีทิศทางกำกับด้วยเรียกกราฟนั้นว่า
กราฟแบบมีทิศทาง(Directed Graphs)
บางครั้งเรียกว่า ไดกราฟ (Digraph)ถ้าต้องการอ้างถึงเอ็จแต่ละเส้นสามารถเขียนชื่อเอ็จกำกับไว้ก็ได้
โดยทั่ว ๆ ไปการเขียนกราฟเพื่อแสดงให้เห็นความสัมพันธ์ ของสิ่งที่เราสนใจแทนโหนดด้วย จุด (pointes)
หรือวงกลม (circles)ที่มีชื่อหรือข้อมูลกำกับ เพื่อบอกความแตกต่างของแต่ละโหนดและเอ็จแทนด้วยเส้น
หรือเส้นโค้งเชื่อมต่อระหว่างโหนดสองโหนดถ้าเป็นกราฟแบบมีทิศทางเส้นหรือเส้นโค้งต้อง
มีหัวลูกศรกำกับทิศทางของความสัมพันธ์ด้วย
กราฟแบบไม่มีทิศทางเป็นเซตแบบจำกัดของโหนดและเอ็จ โดยเซตอาจจะว่างไม่มีโหนดหรือเอ็จเลยเป็นกราฟว่าง (empty graph) แต่ละเอ็จจะเชื่อมระหว่างโหนดสองโหนด หรือเชื่อมตัวเอง เอ็จไม่มีทิศทางกำกับ ลำดับของการเชื่อมต่อกันไม่สำคัญ นั่นคือไม่มีโหนดใดเป็นโหนดแรก (first node) หรือไม่มีโหนดเริ่มต้นไม่มีโหนดใดเป็นโหนดสิ้นสุด ดังนั้นเราอาจจะกล่าวว่าเอ็จเชื่อมโหนด u และโหนด v หรือจะกล่าวว่าเอ็จเชื่อมโหนด v และโหนด u ก็มีความหมายเหมือนกัน

ตัวอย่างกราฟแบบไม่มีทิศทางในรูปแบบต่างๆ
ตัวอย่างกราฟแบบไม่มีทิศทางในรูปแบบต่าง ๆ และโหนดสองโหนดในกราฟแบบไม่มีทิศทางถือว่าเป็นโหนดที่ ใกล้กัน (adjacent) ถ้ามีเอ็จเชื่อมจากโหนดที่หนึ่งไปโหนดที่สอง กราฟ (ก) แสดงกราฟที่มีลักษณะ ต่อเนื่อง (connected) เป็นกราฟที่มีเส้นทางเชื่อมจากโหนดใด ๆ ไปยังโหนดอื่นเสมอ โดยมีโหนด 1 กับโหนด 2 และ โหนด 3 กับ โหนด 4 เป็นโหนดที่ใกล้กัน แต่โหนด 1 และ 4 ไม่ใช่โหนดที่ใกล้กัน กราฟ (ข) แสดงกราฟที่มีลักษณะเป็น วีถี (path) มีเส้นทางเชื่อมไปยังโหนดต่าง ๆ อย่างเป็นลำดับ โดยแต่ละโหนดจะเป็นโหนดที่ใกล้กันกับโหนดที่อยู่ถัดไป กราฟ (ค) แสดงกราฟที่เป็นวัฎจักร (cycle) ซึ่งต้องมีอย่างน้อย 3 โหด ที่โหนดสุดท้ายต้องเชื่อมกับโหนดแรก กราฟ (ง) แสดงกราฟที่มีลักษณะ ไม่ต่อเนื่อง (disconnected) เนื่องจากไม่มีเส้นทางเชื่อมจากโหนด 3 ไปยังโหนดอื่นเลย กราฟ (ก), (ข) และ (ค) ถือว่าเป็นกราฟต่อเนื่อง และกราฟ (จ) แสดงกราฟที่เป็นทรี โดยทรีเป็นกราฟที่ต่อเนื่อง ไม่มีทิศทาง และไม่เป็นวัฏจักร
กราฟแบบมีทิศทาง เป็นเซตแบบจำกัดของโหนดและเอ็จ โดยเซตอาจจะว่างไม่มีโหนดหรือเอ็จเลยเป็นกราฟว่าง (empty graph) แต่ละเอ็จจะเชื่อมระหว่างโหนดสองโหนด เอ็จมีทิศทางกำกับแสดงลำดับของการเชื่อมต่อกัน โดยมีโหนดเริ่มต้น (source node) และโหนดสิ้นสุด (target node)
รูปแบบต่าง ๆ ของกราฟแบบมีทิศทางเหมือนกับรูปแบบของกราฟ ไม่มีทิศทาง ต่างกันตรงที่กราฟแบบนี้จะมีทิศทางกำกับด้วยเท่านั้น

ตัวอย่างกราฟแบบมีทิศทาง
การแทนกราฟในหน่วยความจำ การแทนกราฟในหน่วยความจำด้วยวิธีเก็บเอ็จทั้งหมดใน แถวลำดับ 2 มิติ จะค่อนข้างเปลืองเนื้อที่ เนื่องจากมีบางเอ็จที่เก็บซ้ำอาจหลีกเลี่ยงปัญหานี้ได้โดยใช้แถวลำดับ 2 มิติเก็บโหนดและ พอยเตอร์ชี้ไปยงตำแหน่งของโหนดต่าง ๆ ที่สัมพันธ์ด้วย และใช้ แถวลำดับ1 มิติเก็บโหนดต่าง ๆ ที่มีความสัมพันธ์กับโหนดในแถวลำดับ 2 มิติ
การจัดเก็บกราฟด้วยวิธีเก็บโหนดและพอยน์เตอร์นี้ยุ่งยากในการจัดการเพิ่มขึ้นเนื่องจากต้องเก็บโหนดและพอยน์เตอร์ในแถวลำดับ 2 มิติ และต้องจัดเก็บโหนดที่สัมพันธ์ด้วยในแถวลำดับ 1 มิติ อย่างไรก็ตามทั้งสองวิธีที่กล่าวมาข้างต้นไม่เหมาะกับกราฟที่มีการเปลี่ยนแปลงตลอดเวลา ควรใช้ในกราฟที่ไม่มีการเปลี่ยนแปลงตลอดอายุขัยของการใช้งาน เพราะถ้ามีการเปลี่ยนแปลงส่วนใดส่วนหนึ่งของกราฟจะกระทบกับส่วนอื่น ๆ ที่อยู่ในระดับที่ต่ำกว่าด้วยเสมอ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา อาจจะใช้วิธีแอดจาเซนซีลิสต์ (adjacency list) ซึ่งเป็นวิธีที่คล้ายวิธีจัดเก็บกราฟด้วยการเก็บโหนดและพอยน์เตอร์ที่กล่าวมาแล้วข้างต้น แต่ต่างกันตรงที่แทนที่จะเก็บโหนดที่มีความสัมพันธ์ด้วยไว้ในแถวลำดับ 1 มิติ จะใช้ลิงค์ลิสต์แทนเพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับการท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง ดังนั้นเพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำเครื่องหมายมาร์คบิตบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้วเพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี 2 แบบดังนี้
การท่องแบบกว้าง (breadth first traversal) วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
การท่องแบบลึก (depth first traversal) การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตามแนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือนโหนดอื่น ๆ ต่อไปจนครบทุกโหนด
สรุปย่อ
กราฟเป็นโครงสร้างข้อมูลที่นำไปใช้ในงานที่เกี่ยวข้องกับการแก้ปัญหาที่ ค่อนข้างซับซ้อน ตัวอย่างโครงสร้างข้อมูลแบบกราฟ เช่น การวางข่ายงานคอมพิวเตอร์ การวิเคราะห์เส้นทางวิกฤต การวางแผนข่ายงาน และปัญหาเส้นทางที่สั้นที่สุด เป็นต้น ซึ่งกราฟมีนิยามดังนี้
กราฟเป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้นที่ประกอบด้วยกลุ่มของสิ่งสองสิ่ง คือ
- โหนด หรือ เวอร์เทกซ์
- เส้นเชื่อมความสัมพันธ์ระหว่างโหนดเรียว่า เอ็จ
โดยกราฟจะมีอยู่สองประเภทคือ กราฟแบบมีทิศทาง และกราฟแบบไม่มีทิศทาง โดยกราฟแบบมีทิศทางเอ็จมีทิศทางกำกับแสดงลำดับของการเชื่อมต่อ โดยมีโหนดเริ่มต้นและโหนดสิ้นสุด ส่วนกราฟแบบไม่มีทิศทางจะไม่คำนึงถึงลำดับของการเชื่อมต่อกัน ไม่มีโหนดแรกและโหนดสิ้นสุด นอกจากนั้นกราฟมีโครงสร้างหลายรูปแบบเช่น ต่อเนื่อง ไม่ต่อเนื่อง วิถี วัฎจักร และทรี เป็นต้น
การแทนกราฟในความจำหลักวิธีที่ง่ายและตรงไปตรงมาที่สุดคือ การเก็บเอ็จทุก ๆ เอ็จในแถวลำดับ 2 มิติ แต่วิธีนี้ค่อนข้างเปลืองเนื้อที่เนื่องจากมีบางเอ็จที่เก็บซ้ำเดิม อีกวิธีหนึ่งก็คือใช้แถวลำดับ 2 มิติเก็บโหนดและพอยน์เตอร์ชี้ไปยังตำแหน่งโหนดต่าง ๆ ที่สัมพันธ์ด้วย (ใช้แถวลำดับ 1 มิติเก็บโหนดที่สัมพันธ์ด้วย) หรือใช้วิธีแอดจาเซนซีลิสต์โดยใช้ลิงค์ลิสต์แทนแถวลำดับ 1 มิติ อย่างไรก็ตามทั้งสามวิธีที่กล่าวมาไม่เป็นที่นิยม วิธีที่นิยมมากที่สุดคือ การแทนด้วยแอดจาเซนซีเมทริกซ์ โดยถ้ากราฟของเรามี n โหนดต้องสร้างเมทริกซ์จัตุรัสขนาด n x n เช่น และค่าในเมทริกซ์จะเก็บว่าระหว่างโหนดสองโหนดมีคู่ใดบ้างที่มีความสัมพันธ์กัน เราสามารถหาได้ว่ามีเส้นทางขนาดเท่าใด และมีกี่เส้นทาง จากการนำแอดจาเซนซีเมทริกซ์มาคูณด้วยตัวมันเอง
กราฟ (Graph) เป็นโครงสร้างข้อมูลไม่เป็นเชิงเส้น (Nonlinear Data Structure) มีความแตกต่างจากโครงสร้างข้อมูลทรีในบทที่ผ่านมา กราฟเป็นโครงสร้างข้อมูลที่มีการนำไปใช้ในงานที่เกี่ยวข้องกับการแก้ปัญหาที่ค่อนข้างซับซ้อนเช่น การวางข่าย งานคอมพิวเตอร์ การวิเคราะห์เส้นทางวิกฤติ และปัญหาเส้นทางที่สั้นที่สุด เป็นต้น
กราฟ เป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้นที่ประกอบด้วยกลุ่มของสิ่งสองสิ่งคือ
(1) โหนด (nodes) หรือ เวอร์เทกซ์ (vertexes)
(2) เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (edges)
การเขียนกราฟแสดงโหนดและเส้นเชื่อมความสัมพันธ์ระหว่างโหนดไม่มีรูปแบบที่ตายตัว การลากเส้นความสัมพันธ์เป็นเส้นลักษณะไหนก็ได้ที่สามารถแสดง ความสัมพันธ์ระหว่างโหนดได้ถูกต้อง
กราฟที่มีเอ็จเชื่อมระหว่างโหนดสองโหนดถ้าเอ็จไม่มีลำดับ ความสัมพันธ์จะเรียกกราฟนั้นว่า
กราฟแบบไม่มีทิศทาง (Undirected Graphs)
และถ้ากราฟนั้นมีเอ็จที่มีลำดับความสัมพันธ์หรือมีทิศทางกำกับด้วยเรียกกราฟนั้นว่า
กราฟแบบมีทิศทาง(Directed Graphs)
บางครั้งเรียกว่า ไดกราฟ (Digraph)ถ้าต้องการอ้างถึงเอ็จแต่ละเส้นสามารถเขียนชื่อเอ็จกำกับไว้ก็ได้
โดยทั่ว ๆ ไปการเขียนกราฟเพื่อแสดงให้เห็นความสัมพันธ์ ของสิ่งที่เราสนใจแทนโหนดด้วย จุด (pointes)
หรือวงกลม (circles)ที่มีชื่อหรือข้อมูลกำกับ เพื่อบอกความแตกต่างของแต่ละโหนดและเอ็จแทนด้วยเส้น
หรือเส้นโค้งเชื่อมต่อระหว่างโหนดสองโหนดถ้าเป็นกราฟแบบมีทิศทางเส้นหรือเส้นโค้งต้อง
มีหัวลูกศรกำกับทิศทางของความสัมพันธ์ด้วย
กราฟแบบไม่มีทิศทางเป็นเซตแบบจำกัดของโหนดและเอ็จ โดยเซตอาจจะว่างไม่มีโหนดหรือเอ็จเลยเป็นกราฟว่าง (empty graph) แต่ละเอ็จจะเชื่อมระหว่างโหนดสองโหนด หรือเชื่อมตัวเอง เอ็จไม่มีทิศทางกำกับ ลำดับของการเชื่อมต่อกันไม่สำคัญ นั่นคือไม่มีโหนดใดเป็นโหนดแรก (first node) หรือไม่มีโหนดเริ่มต้นไม่มีโหนดใดเป็นโหนดสิ้นสุด ดังนั้นเราอาจจะกล่าวว่าเอ็จเชื่อมโหนด u และโหนด v หรือจะกล่าวว่าเอ็จเชื่อมโหนด v และโหนด u ก็มีความหมายเหมือนกัน

ตัวอย่างกราฟแบบไม่มีทิศทางในรูปแบบต่างๆ
ตัวอย่างกราฟแบบไม่มีทิศทางในรูปแบบต่าง ๆ และโหนดสองโหนดในกราฟแบบไม่มีทิศทางถือว่าเป็นโหนดที่ ใกล้กัน (adjacent) ถ้ามีเอ็จเชื่อมจากโหนดที่หนึ่งไปโหนดที่สอง กราฟ (ก) แสดงกราฟที่มีลักษณะ ต่อเนื่อง (connected) เป็นกราฟที่มีเส้นทางเชื่อมจากโหนดใด ๆ ไปยังโหนดอื่นเสมอ โดยมีโหนด 1 กับโหนด 2 และ โหนด 3 กับ โหนด 4 เป็นโหนดที่ใกล้กัน แต่โหนด 1 และ 4 ไม่ใช่โหนดที่ใกล้กัน กราฟ (ข) แสดงกราฟที่มีลักษณะเป็น วีถี (path) มีเส้นทางเชื่อมไปยังโหนดต่าง ๆ อย่างเป็นลำดับ โดยแต่ละโหนดจะเป็นโหนดที่ใกล้กันกับโหนดที่อยู่ถัดไป กราฟ (ค) แสดงกราฟที่เป็นวัฎจักร (cycle) ซึ่งต้องมีอย่างน้อย 3 โหด ที่โหนดสุดท้ายต้องเชื่อมกับโหนดแรก กราฟ (ง) แสดงกราฟที่มีลักษณะ ไม่ต่อเนื่อง (disconnected) เนื่องจากไม่มีเส้นทางเชื่อมจากโหนด 3 ไปยังโหนดอื่นเลย กราฟ (ก), (ข) และ (ค) ถือว่าเป็นกราฟต่อเนื่อง และกราฟ (จ) แสดงกราฟที่เป็นทรี โดยทรีเป็นกราฟที่ต่อเนื่อง ไม่มีทิศทาง และไม่เป็นวัฏจักร
กราฟแบบมีทิศทาง เป็นเซตแบบจำกัดของโหนดและเอ็จ โดยเซตอาจจะว่างไม่มีโหนดหรือเอ็จเลยเป็นกราฟว่าง (empty graph) แต่ละเอ็จจะเชื่อมระหว่างโหนดสองโหนด เอ็จมีทิศทางกำกับแสดงลำดับของการเชื่อมต่อกัน โดยมีโหนดเริ่มต้น (source node) และโหนดสิ้นสุด (target node)
รูปแบบต่าง ๆ ของกราฟแบบมีทิศทางเหมือนกับรูปแบบของกราฟ ไม่มีทิศทาง ต่างกันตรงที่กราฟแบบนี้จะมีทิศทางกำกับด้วยเท่านั้น

ตัวอย่างกราฟแบบมีทิศทาง
การแทนกราฟในหน่วยความจำ การแทนกราฟในหน่วยความจำด้วยวิธีเก็บเอ็จทั้งหมดใน แถวลำดับ 2 มิติ จะค่อนข้างเปลืองเนื้อที่ เนื่องจากมีบางเอ็จที่เก็บซ้ำอาจหลีกเลี่ยงปัญหานี้ได้โดยใช้แถวลำดับ 2 มิติเก็บโหนดและ พอยเตอร์ชี้ไปยงตำแหน่งของโหนดต่าง ๆ ที่สัมพันธ์ด้วย และใช้ แถวลำดับ1 มิติเก็บโหนดต่าง ๆ ที่มีความสัมพันธ์กับโหนดในแถวลำดับ 2 มิติ
การจัดเก็บกราฟด้วยวิธีเก็บโหนดและพอยน์เตอร์นี้ยุ่งยากในการจัดการเพิ่มขึ้นเนื่องจากต้องเก็บโหนดและพอยน์เตอร์ในแถวลำดับ 2 มิติ และต้องจัดเก็บโหนดที่สัมพันธ์ด้วยในแถวลำดับ 1 มิติ อย่างไรก็ตามทั้งสองวิธีที่กล่าวมาข้างต้นไม่เหมาะกับกราฟที่มีการเปลี่ยนแปลงตลอดเวลา ควรใช้ในกราฟที่ไม่มีการเปลี่ยนแปลงตลอดอายุขัยของการใช้งาน เพราะถ้ามีการเปลี่ยนแปลงส่วนใดส่วนหนึ่งของกราฟจะกระทบกับส่วนอื่น ๆ ที่อยู่ในระดับที่ต่ำกว่าด้วยเสมอ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา อาจจะใช้วิธีแอดจาเซนซีลิสต์ (adjacency list) ซึ่งเป็นวิธีที่คล้ายวิธีจัดเก็บกราฟด้วยการเก็บโหนดและพอยน์เตอร์ที่กล่าวมาแล้วข้างต้น แต่ต่างกันตรงที่แทนที่จะเก็บโหนดที่มีความสัมพันธ์ด้วยไว้ในแถวลำดับ 1 มิติ จะใช้ลิงค์ลิสต์แทนเพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับการท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง ดังนั้นเพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำเครื่องหมายมาร์คบิตบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้วเพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี 2 แบบดังนี้
การท่องแบบกว้าง (breadth first traversal) วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
การท่องแบบลึก (depth first traversal) การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตามแนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือนโหนดอื่น ๆ ต่อไปจนครบทุกโหนด
สรุปย่อ
กราฟเป็นโครงสร้างข้อมูลที่นำไปใช้ในงานที่เกี่ยวข้องกับการแก้ปัญหาที่ ค่อนข้างซับซ้อน ตัวอย่างโครงสร้างข้อมูลแบบกราฟ เช่น การวางข่ายงานคอมพิวเตอร์ การวิเคราะห์เส้นทางวิกฤต การวางแผนข่ายงาน และปัญหาเส้นทางที่สั้นที่สุด เป็นต้น ซึ่งกราฟมีนิยามดังนี้
กราฟเป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้นที่ประกอบด้วยกลุ่มของสิ่งสองสิ่ง คือ
- โหนด หรือ เวอร์เทกซ์
- เส้นเชื่อมความสัมพันธ์ระหว่างโหนดเรียว่า เอ็จ
โดยกราฟจะมีอยู่สองประเภทคือ กราฟแบบมีทิศทาง และกราฟแบบไม่มีทิศทาง โดยกราฟแบบมีทิศทางเอ็จมีทิศทางกำกับแสดงลำดับของการเชื่อมต่อ โดยมีโหนดเริ่มต้นและโหนดสิ้นสุด ส่วนกราฟแบบไม่มีทิศทางจะไม่คำนึงถึงลำดับของการเชื่อมต่อกัน ไม่มีโหนดแรกและโหนดสิ้นสุด นอกจากนั้นกราฟมีโครงสร้างหลายรูปแบบเช่น ต่อเนื่อง ไม่ต่อเนื่อง วิถี วัฎจักร และทรี เป็นต้น
การแทนกราฟในความจำหลักวิธีที่ง่ายและตรงไปตรงมาที่สุดคือ การเก็บเอ็จทุก ๆ เอ็จในแถวลำดับ 2 มิติ แต่วิธีนี้ค่อนข้างเปลืองเนื้อที่เนื่องจากมีบางเอ็จที่เก็บซ้ำเดิม อีกวิธีหนึ่งก็คือใช้แถวลำดับ 2 มิติเก็บโหนดและพอยน์เตอร์ชี้ไปยังตำแหน่งโหนดต่าง ๆ ที่สัมพันธ์ด้วย (ใช้แถวลำดับ 1 มิติเก็บโหนดที่สัมพันธ์ด้วย) หรือใช้วิธีแอดจาเซนซีลิสต์โดยใช้ลิงค์ลิสต์แทนแถวลำดับ 1 มิติ อย่างไรก็ตามทั้งสามวิธีที่กล่าวมาไม่เป็นที่นิยม วิธีที่นิยมมากที่สุดคือ การแทนด้วยแอดจาเซนซีเมทริกซ์ โดยถ้ากราฟของเรามี n โหนดต้องสร้างเมทริกซ์จัตุรัสขนาด n x n เช่น และค่าในเมทริกซ์จะเก็บว่าระหว่างโหนดสองโหนดมีคู่ใดบ้างที่มีความสัมพันธ์กัน เราสามารถหาได้ว่ามีเส้นทางขนาดเท่าใด และมีกี่เส้นทาง จากการนำแอดจาเซนซีเมทริกซ์มาคูณด้วยตัวมันเอง
วันจันทร์ที่ 31 สิงหาคม พ.ศ. 2552
DTS 07-25/8/52
สรุปบทเรียน ทรี
โครงสร้างข้อมูลแบบทรี
ทรี (Tree) เป็นโครงสร้างข้อมูลที่ความสัมพันธ์ ระหว่างโหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับชั้น (Hierarchical Relationship) ได้มีการนำรูปแบบทรีไปประยุกต์ใช้ในงานต่าง ๆ อย่างแพร่หลาย ส่วนมากจะใช้สำหรับแสดงความสัมพันธ์ระหว่างข้อมูล เช่น แผนผังองค์ประกอบของหน่วยงานต่าง ๆ โครงสร้างสารบัญหนังสือ แต่ละโหนดจะมีความสัมพันธ์กับโหนดในระดับที่ต่ำลงมาหนึ่งระดับได้หลาย ๆ โนด เรียกโหนดดังกล่าวว่า โหนดแม่ (Parent or Mother Node) โหนดที่อยู่ต่ำกว่าโหนดแม่อยู่หนึ่งระดับ เรียกว่า โหนดลูก(Child or Sun Node) โหนดที่อยู่ในระดับสูงสุดและไม่มีโหนดแม่ เรียกว่า โหนดราก (Root Node) โหนดที่มีโหนดแม่เป็นโหนดเดียวกัน เรียกว่า โหนดพี่น้อง (Siblings) โหนดที่ไม่มีโหนดลูก เรียกว่า โหนดใบ (Leave Node) เส้นเชื่อมแสดงความสัมพันธ์ระหว่างโหนดสองโหนดเรียกว่า กิ่ง (Branch) Ancestor Node หรือ บรรพบุรุษของโหนดใด ๆ หมายถึง โหนดที่มาก่อนโหนดใด ๆ Decendant Node หรือ ผู้สืบสกุล หมายถึง โหนดที่ตามหลังโหนดใด ๆ
นิยามของทรี
1. นิยามทรีด้วยนิยามของกราฟ
ทรี คือ กราฟที่ต่อเนื่องโดยไม่มีวงจรปิด (loop) ในโครงสร้าง โหนดสองโหนดใด ๆ ในทรีต้องมีทางติดต่อกันทางเดียวเท่านั้น และทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น
การเขียนรูปแบบทรี อาจเขียนได้ 4 แบบ คือ

2. นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ
ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ถ้าว่าง ไม่มีโหนดเลย เรียกว่า นัลทรี (Null Tree) และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือจะแบ่งเป็นทรีย่อย (Sub Tree) T1, T2, T3,…,Tk โดยที่ k>=0 และทรีย่อยต้องมีคุณสมบัติเป็นทรี
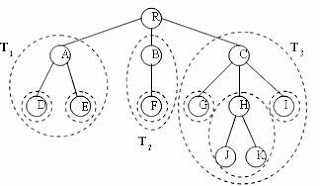
3. นิยามที่เกี่ยวข้องกับทรี
1. ฟอร์เรสต์ (Forest) หมายถึง กลุ่มของทรีที่เกิดจากการเอาโหนดรากของทรีออก หรือ เซตของทรีที่แยกจากกัน (Disjoint Trees)

2. ทรีที่มีแบบแผน (Ordered Tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมีความสัมพันธ์ที่แน่นอน เช่น ไปทางขวาไปทางซ้าย เป็นต้น
3. ทรีคล้าย (Similar Tree) คือ ทรีที่มีโครงสร้างเหมือนกัน หรือทรีที่มีรูปร่างของทรีเหมือนกัน โดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด
4.ทรีเหมือน (Equivalent Tree) คือ ทรีที่เหมือนกันโดยสมบูรณ์ โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
5. กำลัง (Degree) หมายถึง จำนวนทรีย่อยของโหนดนั้น ๆ เช่น
6. ระดับของโหนด (Level of Node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจาก
โหนดราก เมื่อกำหนดให้โหนดรากของทรีนั้นอยู่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมด คือ ยาวเท่ากับ 1 หน่วย ซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1 และจำนวนเส้นทางตามแนวดิ่งของโหนดใด ๆ ซึ่งห่างจากโหนดราก เรียกว่า ความสูง (Height) หรือความลึก (Depth)
แทนทรีด้วยไบนารีทรี เป็นวิธีแก้ปัญหาเพื่อลดการ สิ้นเปลืองเนื้อที่ในหน่วยความจำก็คือ กำหนดลิงค์ฟิลด์ให้มีจำนวนน้อยที่สุดเท่าที่จำเป็นเท่านั้น โดยกำหนดให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์สองลิงค์ฟิลด์ ให้ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดพี่น้องที่เป็นโหนดถัดไป โหนดใดไม่มีโหนดลูกหรือไม่มีโหนดพี่น้องให้ค่าพอยน์เตอร์ในลิงค์ฟิลด์มีค่าเป็น Null
เป็นโครงสร้างข้อมูลแบบต้นไม้เช่นเดียวกับ Tree โดยประกอบด้วย Root node เพียงโหนดเดียวเท่านั้น โหนดที่เหลือจัดเป็นโหนดลูก (Child node) ซึ่งสามารถมีได้ตั้งแต่ 0 โหนด จนถึง 2 โหนด และโหนดลูกแต่ละโหนดสามารถเป็นโหนดแม่ (Parent node) ซึ่งแต่ละโหนดสามารถมีโหนดลูกได้ตั้งแต่ 0 จนถึง 2 โหนดเช่นเดียวกัน
สรุปได้ว่า ไบนารีทรี คือ โหนดทุกโหนดใน Binary tree จะมีลูกไม่เกินสอง คือ 0 , 1 หรือ 2

จะได้โครงสร้างทรีที่แต่ละโหนดมีลิงค์ฟิลด์แค่สองลิงค์ฟิลด์ ซึ่งช่วยให้ประหยัดเนื้อที่ในการจัดเก็บได้มาก เรียกโครงสร้างทรีที่แต่ละโหนดมีจำนวนโหนดลูกไม่เกินสอง หรือแต่ละโหนดมีจำนวนทรีย่อยไม่เกินสองนี้ว่า ไบนารีทรี (Binary Tree)
การท่องไปในทรี
การท่องไปในไบนารีทรีเป็นการเข้าไปเยือนโหนดทุกโหนดในทรีอย่างมีระบบซึ่งมีวิธีการเดินที่นิยมใช้อยู่ 3 วิธีคือ การท่องแบบพรีออร์เดอร์ การท่องแบบอินออร์เดอร์ และการท่องแบบโพสออร์เดอร์
โครงสร้างไบนารีทรีสามารถนำไปประยุกต์ใช้ในการเก็บนิพจน์คณิตศาสตร์ เรียกทรีนั้นว่า เอ็กซ์เพรสชันทรี แต่ละโหนดจะเก็บตัวดำเนินการและตัวถูกดำเนินการของนิพจน์คณิตศาสตร์ เมื่อเราท่องไปในเอ็กซ์เพรสชันทรีในแบบต่าง ๆ จะได้นิพจน์ในรูปแบบต่าง ๆ กันคือ ถ้าท่องแบบพรีออร์เดอร์ได้นิพจน์พรีฟิกซ์ ถ้าท่องแบบอินออร์เดอร์ได้นิพจน์อินฟิกซ์ และถ้าท่องแบบโพสออร์เดอร์ได้นิพจน์แบบโพสฟิกซ์ เป็นต้น
ไบนารีเซิรชทรีเป็นไบนารีทรีที่มีคุณสมบัติว่า ทุกโหนดในทรีค่าของโหนดรากมีค่ามากกว่าค่าของโหนดในทรีย่อยทางซ้ายและมีค่าน้อยกว่าหรือเท่ากับค่าของโหนดใน ทรีย่อยทางขวา และในแต่ละทรีย่อยก็มีเช่นเดียวกัน การค้นหาข้อมูลในไบนารีเซิรชทรี ทำให้การค้นหาข้อมูลใด ๆ ใช้เวลาน้อยลง เนื่องจากการค้นหาจะใช้ความสัมพันธ์ภายในโครงสร้างทำให้การค้นหาเร็วขึ้น นอกจากนี้ถ้าท่องไปในไบนารีเซิรชทรีแบบอินออร์เดอร์จะได้ข้อมูลเรียงลำดับจากน้อยไปมาก
โครงสร้างข้อมูลแบบทรี
ทรี (Tree) เป็นโครงสร้างข้อมูลที่ความสัมพันธ์ ระหว่างโหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับชั้น (Hierarchical Relationship) ได้มีการนำรูปแบบทรีไปประยุกต์ใช้ในงานต่าง ๆ อย่างแพร่หลาย ส่วนมากจะใช้สำหรับแสดงความสัมพันธ์ระหว่างข้อมูล เช่น แผนผังองค์ประกอบของหน่วยงานต่าง ๆ โครงสร้างสารบัญหนังสือ แต่ละโหนดจะมีความสัมพันธ์กับโหนดในระดับที่ต่ำลงมาหนึ่งระดับได้หลาย ๆ โนด เรียกโหนดดังกล่าวว่า โหนดแม่ (Parent or Mother Node) โหนดที่อยู่ต่ำกว่าโหนดแม่อยู่หนึ่งระดับ เรียกว่า โหนดลูก(Child or Sun Node) โหนดที่อยู่ในระดับสูงสุดและไม่มีโหนดแม่ เรียกว่า โหนดราก (Root Node) โหนดที่มีโหนดแม่เป็นโหนดเดียวกัน เรียกว่า โหนดพี่น้อง (Siblings) โหนดที่ไม่มีโหนดลูก เรียกว่า โหนดใบ (Leave Node) เส้นเชื่อมแสดงความสัมพันธ์ระหว่างโหนดสองโหนดเรียกว่า กิ่ง (Branch) Ancestor Node หรือ บรรพบุรุษของโหนดใด ๆ หมายถึง โหนดที่มาก่อนโหนดใด ๆ Decendant Node หรือ ผู้สืบสกุล หมายถึง โหนดที่ตามหลังโหนดใด ๆ
นิยามของทรี
1. นิยามทรีด้วยนิยามของกราฟ
ทรี คือ กราฟที่ต่อเนื่องโดยไม่มีวงจรปิด (loop) ในโครงสร้าง โหนดสองโหนดใด ๆ ในทรีต้องมีทางติดต่อกันทางเดียวเท่านั้น และทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น
การเขียนรูปแบบทรี อาจเขียนได้ 4 แบบ คือ

2. นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ
ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ถ้าว่าง ไม่มีโหนดเลย เรียกว่า นัลทรี (Null Tree) และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือจะแบ่งเป็นทรีย่อย (Sub Tree) T1, T2, T3,…,Tk โดยที่ k>=0 และทรีย่อยต้องมีคุณสมบัติเป็นทรี

3. นิยามที่เกี่ยวข้องกับทรี
1. ฟอร์เรสต์ (Forest) หมายถึง กลุ่มของทรีที่เกิดจากการเอาโหนดรากของทรีออก หรือ เซตของทรีที่แยกจากกัน (Disjoint Trees)

2. ทรีที่มีแบบแผน (Ordered Tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมีความสัมพันธ์ที่แน่นอน เช่น ไปทางขวาไปทางซ้าย เป็นต้น
3. ทรีคล้าย (Similar Tree) คือ ทรีที่มีโครงสร้างเหมือนกัน หรือทรีที่มีรูปร่างของทรีเหมือนกัน โดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด
4.ทรีเหมือน (Equivalent Tree) คือ ทรีที่เหมือนกันโดยสมบูรณ์ โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
5. กำลัง (Degree) หมายถึง จำนวนทรีย่อยของโหนดนั้น ๆ เช่น
6. ระดับของโหนด (Level of Node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจาก
โหนดราก เมื่อกำหนดให้โหนดรากของทรีนั้นอยู่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมด คือ ยาวเท่ากับ 1 หน่วย ซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1 และจำนวนเส้นทางตามแนวดิ่งของโหนดใด ๆ ซึ่งห่างจากโหนดราก เรียกว่า ความสูง (Height) หรือความลึก (Depth)
แทนทรีด้วยไบนารีทรี เป็นวิธีแก้ปัญหาเพื่อลดการ สิ้นเปลืองเนื้อที่ในหน่วยความจำก็คือ กำหนดลิงค์ฟิลด์ให้มีจำนวนน้อยที่สุดเท่าที่จำเป็นเท่านั้น โดยกำหนดให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์สองลิงค์ฟิลด์ ให้ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดพี่น้องที่เป็นโหนดถัดไป โหนดใดไม่มีโหนดลูกหรือไม่มีโหนดพี่น้องให้ค่าพอยน์เตอร์ในลิงค์ฟิลด์มีค่าเป็น Null
เป็นโครงสร้างข้อมูลแบบต้นไม้เช่นเดียวกับ Tree โดยประกอบด้วย Root node เพียงโหนดเดียวเท่านั้น โหนดที่เหลือจัดเป็นโหนดลูก (Child node) ซึ่งสามารถมีได้ตั้งแต่ 0 โหนด จนถึง 2 โหนด และโหนดลูกแต่ละโหนดสามารถเป็นโหนดแม่ (Parent node) ซึ่งแต่ละโหนดสามารถมีโหนดลูกได้ตั้งแต่ 0 จนถึง 2 โหนดเช่นเดียวกัน
สรุปได้ว่า ไบนารีทรี คือ โหนดทุกโหนดใน Binary tree จะมีลูกไม่เกินสอง คือ 0 , 1 หรือ 2

จะได้โครงสร้างทรีที่แต่ละโหนดมีลิงค์ฟิลด์แค่สองลิงค์ฟิลด์ ซึ่งช่วยให้ประหยัดเนื้อที่ในการจัดเก็บได้มาก เรียกโครงสร้างทรีที่แต่ละโหนดมีจำนวนโหนดลูกไม่เกินสอง หรือแต่ละโหนดมีจำนวนทรีย่อยไม่เกินสองนี้ว่า ไบนารีทรี (Binary Tree)
การท่องไปในทรี
การท่องไปในไบนารีทรีเป็นการเข้าไปเยือนโหนดทุกโหนดในทรีอย่างมีระบบซึ่งมีวิธีการเดินที่นิยมใช้อยู่ 3 วิธีคือ การท่องแบบพรีออร์เดอร์ การท่องแบบอินออร์เดอร์ และการท่องแบบโพสออร์เดอร์
โครงสร้างไบนารีทรีสามารถนำไปประยุกต์ใช้ในการเก็บนิพจน์คณิตศาสตร์ เรียกทรีนั้นว่า เอ็กซ์เพรสชันทรี แต่ละโหนดจะเก็บตัวดำเนินการและตัวถูกดำเนินการของนิพจน์คณิตศาสตร์ เมื่อเราท่องไปในเอ็กซ์เพรสชันทรีในแบบต่าง ๆ จะได้นิพจน์ในรูปแบบต่าง ๆ กันคือ ถ้าท่องแบบพรีออร์เดอร์ได้นิพจน์พรีฟิกซ์ ถ้าท่องแบบอินออร์เดอร์ได้นิพจน์อินฟิกซ์ และถ้าท่องแบบโพสออร์เดอร์ได้นิพจน์แบบโพสฟิกซ์ เป็นต้น
ไบนารีเซิรชทรีเป็นไบนารีทรีที่มีคุณสมบัติว่า ทุกโหนดในทรีค่าของโหนดรากมีค่ามากกว่าค่าของโหนดในทรีย่อยทางซ้ายและมีค่าน้อยกว่าหรือเท่ากับค่าของโหนดใน ทรีย่อยทางขวา และในแต่ละทรีย่อยก็มีเช่นเดียวกัน การค้นหาข้อมูลในไบนารีเซิรชทรี ทำให้การค้นหาข้อมูลใด ๆ ใช้เวลาน้อยลง เนื่องจากการค้นหาจะใช้ความสัมพันธ์ภายในโครงสร้างทำให้การค้นหาเร็วขึ้น นอกจากนี้ถ้าท่องไปในไบนารีเซิรชทรีแบบอินออร์เดอร์จะได้ข้อมูลเรียงลำดับจากน้อยไปมาก
วันเสาร์ที่ 22 สิงหาคม พ.ศ. 2552
DTS 05-08-09
สรุปคิว (Queue)
คิว (queue) คือโครงสร้างข้อมูลที่มีลักษณะเป็นแบบเชิงเส้นตรง (Linear list) มีปลายเปิด 2ด้านซึ่ง
1. การนำข้อมูลเข้า (enqueue) นำข้อมูลเข้าที่ปลายด้านหลังของโครงสร้างคิว
2. การนำข้อมูลออก (dequeue) นำข้อมูลออกที่ปลายด้านหน้าของโครงสร้างคิว
คุณสมบัตินี้เรียกว่า “เข้าก่อนออกก่อน” (First come, first serve หรือ first in, first out: FIFO) ในคิว ผู้ที่อยู่หน้าจะได้ซื้อตั๋วหนังหรือได้รับการบริการก่อน
ตัวอย่างการใช้
1. คนเข้าคิวซื้อตั๋วหนัง
2. นักศึกษาเข้าคิวเพื่อรับบริการในธนาคาร
3. นักศึกษาเข้าคิวซื้ออาหาร
4. ลูกค้าเข้าคิวจ่ายเงินที่เค้าเตอร์
การแทนที่ข้อมูลของคิว
สามารถทำได้ 2 วิธี คือ
1. การแทนที่ข้อมูลของคิวแบบลิงค์ลิสต์
2. การแทนที่ข้อมูลของคิวแบบอะเรย์
การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์
จะประกอบไปด้วย 2 ส่วน คือ
1. Head Nodeจะประกอบไปด้วย 3 ส่วนคือพอยเตอร์จำนวน 2 ตัว คือ Front และ rearกับจำนวนสมาชิกในคิว
2. Data Node จะประกอบไปด้วยข้อมูล (Data) และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
การดำเนินการเกี่ยวกับคิว
การดำเนินการเกี่ยวกับคิว ได้แก่
1. Create Queueจัดสรรหน่วยความจำให้แก่ Head Node และให้ค่า pointer ทั้ง 2 ตัวมีค่าเป็น null และจำนวนสมาชิกเป็น 0
2. Enqueueการเพิ่มข้อมูลเข้าไปในคิว
3. Dequeueการนำข้อมูลออกจากคิว
4. Queue Frontเป็นการนำข้อมูลที่อยู่ส่วนต้นของคิวมาแสดง
5. Queue Rearเป็นการนำข้อมูลที่อยู่ส่วนท้ายของคิวมาแสดง
6. Empty Queueเป็นการตรวจสอบว่าคิวว่างหรือไม่
7. Full Queue เป็นการตรวจสอบว่าคิวเต็มหรือไม่
8. Queue Countเป็นการนับจำนวนสมาชิกที่อยู่ในคิว
9. Destroy Queueเป็นการลบข้อมูลทั้งหมดที่อยู่ในคิว
การนำข้อมูลเข้าสู่คิว จะไม่สามารถนำเข้าในขณะที่คิวเต็ม หรือไม่มีที่ว่าง ถ้าพยายามนำเข้าจะทำให้เกิดความผิดพลาดที่เรียกว่า overflowการนำข้อมูลออกจากคิว จะไม่สามารถนำอะไรออกจากคิวที่ว่างเปล่าได้ ถ้าพยายามจะทำ
ให้เกิดความผิดพลาดที่เรียกว่าunderflow
การประยุกต์ใช้งานคิวในการจำลองแบบ
การจำลองแบบ (Simulation) หมายถึง การใช้ระบบหนึ่งเพื่อเลียนแบบพฤติกรรมของอีกระบบหนึ่ง ใช้งานเมื่อการทดลองด้วยระบบจริงๆ มีค่าใช้จ่ายสูง หรือเสี่ยงต่ออันตราย การจำลองแบบของคอมพิวเตอร์ จะใช้ขั้นตอนการทำงานของโปรแกรม เพื่อการเลียนแบบพฤติกรรมของระบบที่เราต้องการศึกษา
การจำลองแบบของระบบแบ่งกันใช้เวลา
ระบบคอมพิวเตอร์ที่มีการทำงานแบบแบ่งกันใช้เวลา เป็นระบบที่มีผู้ใช้เครื่องคอมพิวเตอร์พร้อมกันในเวลาเดียวกัน โดยระบบมีหน่วยผลกลาง (ซีพียู) และหน่วยความจำหลักเพียงอย่างละ 1 เท่านั้น ผู้ใช้หลายๆ คนนี้ จะต้องมีการใช้หน่วยความจำหลักและหน่วยประมวลผลกลางร่วมกัน ซึ่งอนุญาติให้ผู้ใช้แต่ละคนประมวลผลโปรแกรม (ใช้ทรัพยากรของระบบ) ในเวลาหนึ่งๆ แล้วก็จะให้ผู้ใช้คนต่อไปใช้จนกว่าจะวนกลับมายังผู้ใช้คนแรกอีก วิธีการประมวลผลร่วมกันระหว่างผู้ใช้หลายๆ คน เราเรียกว่า ระบบแบ่งกันใช้เวลา (Time sharing) ซึ่งลักษณะการใช้ซีพียูจะเป็นไปตามลำดับคือ “มาก่อนได้ก่อน” (first – come – first – serve) และมีลำดับการทำงานดังนี้
1. เมื่อโปรแกรมขอใช้เวลาซีพียู โปรแกรมนั้นจะถูกนำไปต่อท้ายคิวประมวลผล
2. โปรแกรมที่อยู่ต้นคิวจะถูกส่งไปทำงาน และยังคงอยู่ที่ต้นคิวจนกว่าจะใช้ซีพียูเสร็จ
3. เมื่อรันโปรแกรมทำงานเสร็จตามเวลาการขอใช้ซีพียู ก็จะถูกนำออกจากคิว และจะไม่ถูกนำกลับมาอีก จนกว่าจะมีการขอใช้ซีพียูครั้งใหม่ (จึงจะกลับไปที่ข้อ 1. อีก)
คิว (queue) คือโครงสร้างข้อมูลที่มีลักษณะเป็นแบบเชิงเส้นตรง (Linear list) มีปลายเปิด 2ด้านซึ่ง
1. การนำข้อมูลเข้า (enqueue) นำข้อมูลเข้าที่ปลายด้านหลังของโครงสร้างคิว
2. การนำข้อมูลออก (dequeue) นำข้อมูลออกที่ปลายด้านหน้าของโครงสร้างคิว
คุณสมบัตินี้เรียกว่า “เข้าก่อนออกก่อน” (First come, first serve หรือ first in, first out: FIFO) ในคิว ผู้ที่อยู่หน้าจะได้ซื้อตั๋วหนังหรือได้รับการบริการก่อน
ตัวอย่างการใช้
1. คนเข้าคิวซื้อตั๋วหนัง
2. นักศึกษาเข้าคิวเพื่อรับบริการในธนาคาร
3. นักศึกษาเข้าคิวซื้ออาหาร
4. ลูกค้าเข้าคิวจ่ายเงินที่เค้าเตอร์
การแทนที่ข้อมูลของคิว
สามารถทำได้ 2 วิธี คือ
1. การแทนที่ข้อมูลของคิวแบบลิงค์ลิสต์
2. การแทนที่ข้อมูลของคิวแบบอะเรย์
การแทนที่ข้อมูลของสแตกแบบลิงค์ลิสต์
จะประกอบไปด้วย 2 ส่วน คือ
1. Head Nodeจะประกอบไปด้วย 3 ส่วนคือพอยเตอร์จำนวน 2 ตัว คือ Front และ rearกับจำนวนสมาชิกในคิว
2. Data Node จะประกอบไปด้วยข้อมูล (Data) และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
การดำเนินการเกี่ยวกับคิว
การดำเนินการเกี่ยวกับคิว ได้แก่
1. Create Queueจัดสรรหน่วยความจำให้แก่ Head Node และให้ค่า pointer ทั้ง 2 ตัวมีค่าเป็น null และจำนวนสมาชิกเป็น 0
2. Enqueueการเพิ่มข้อมูลเข้าไปในคิว
3. Dequeueการนำข้อมูลออกจากคิว
4. Queue Frontเป็นการนำข้อมูลที่อยู่ส่วนต้นของคิวมาแสดง
5. Queue Rearเป็นการนำข้อมูลที่อยู่ส่วนท้ายของคิวมาแสดง
6. Empty Queueเป็นการตรวจสอบว่าคิวว่างหรือไม่
7. Full Queue เป็นการตรวจสอบว่าคิวเต็มหรือไม่
8. Queue Countเป็นการนับจำนวนสมาชิกที่อยู่ในคิว
9. Destroy Queueเป็นการลบข้อมูลทั้งหมดที่อยู่ในคิว
การนำข้อมูลเข้าสู่คิว จะไม่สามารถนำเข้าในขณะที่คิวเต็ม หรือไม่มีที่ว่าง ถ้าพยายามนำเข้าจะทำให้เกิดความผิดพลาดที่เรียกว่า overflowการนำข้อมูลออกจากคิว จะไม่สามารถนำอะไรออกจากคิวที่ว่างเปล่าได้ ถ้าพยายามจะทำ
ให้เกิดความผิดพลาดที่เรียกว่าunderflow
การประยุกต์ใช้งานคิวในการจำลองแบบ
การจำลองแบบ (Simulation) หมายถึง การใช้ระบบหนึ่งเพื่อเลียนแบบพฤติกรรมของอีกระบบหนึ่ง ใช้งานเมื่อการทดลองด้วยระบบจริงๆ มีค่าใช้จ่ายสูง หรือเสี่ยงต่ออันตราย การจำลองแบบของคอมพิวเตอร์ จะใช้ขั้นตอนการทำงานของโปรแกรม เพื่อการเลียนแบบพฤติกรรมของระบบที่เราต้องการศึกษา
การจำลองแบบของระบบแบ่งกันใช้เวลา
ระบบคอมพิวเตอร์ที่มีการทำงานแบบแบ่งกันใช้เวลา เป็นระบบที่มีผู้ใช้เครื่องคอมพิวเตอร์พร้อมกันในเวลาเดียวกัน โดยระบบมีหน่วยผลกลาง (ซีพียู) และหน่วยความจำหลักเพียงอย่างละ 1 เท่านั้น ผู้ใช้หลายๆ คนนี้ จะต้องมีการใช้หน่วยความจำหลักและหน่วยประมวลผลกลางร่วมกัน ซึ่งอนุญาติให้ผู้ใช้แต่ละคนประมวลผลโปรแกรม (ใช้ทรัพยากรของระบบ) ในเวลาหนึ่งๆ แล้วก็จะให้ผู้ใช้คนต่อไปใช้จนกว่าจะวนกลับมายังผู้ใช้คนแรกอีก วิธีการประมวลผลร่วมกันระหว่างผู้ใช้หลายๆ คน เราเรียกว่า ระบบแบ่งกันใช้เวลา (Time sharing) ซึ่งลักษณะการใช้ซีพียูจะเป็นไปตามลำดับคือ “มาก่อนได้ก่อน” (first – come – first – serve) และมีลำดับการทำงานดังนี้
1. เมื่อโปรแกรมขอใช้เวลาซีพียู โปรแกรมนั้นจะถูกนำไปต่อท้ายคิวประมวลผล
2. โปรแกรมที่อยู่ต้นคิวจะถูกส่งไปทำงาน และยังคงอยู่ที่ต้นคิวจนกว่าจะใช้ซีพียูเสร็จ
3. เมื่อรันโปรแกรมทำงานเสร็จตามเวลาการขอใช้ซีพียู ก็จะถูกนำออกจากคิว และจะไม่ถูกนำกลับมาอีก จนกว่าจะมีการขอใช้ซีพียูครั้งใหม่ (จึงจะกลับไปที่ข้อ 1. อีก)
วันจันทร์ที่ 27 กรกฎาคม พ.ศ. 2552
DTS 05-22/7/52
สรุปบทเรียน สแตก
สแตกเป็นโครงสร้างข้อมูลชนิดหนึ่งซึ่งมีการจัดการข้อมูลแบบ LIFO ( Last In First Out ) คือ ลำดับของข้อมูลที่ถูกนำมาเก็บก่อนจะถูกนำไปใช้ทีหลัง เหมือนกับวาง จานซ้อนกัน เวลาเราจะหยิบจานไปใช้ เราต้องหยิบใบบนสุดก่อน ซึ่งเป็นจานที่ถูกวางเก็บเป็นอันดับ สุดท้าย ส่วนจานที่ถูกวางเก็บเป็นใบแรกจะนำไปใช้ได้ก็ต่อเมื่อนำจานที่วางทับมันอยู่ออกไปใช้เสียก่อน
การทำงานของสแตกจะประกอบด้วย
กระบวนการ 3 กระบวนการที่สำคัญ คือ
1. การนำข้อมูลเข้าสู่สแตก ( Insertion ) คือการนำข้อมูลเข้าไปเก็บไว้ในสแตก ซึ่งการกระทำเช่นนี้ เราเรียกว่า PUSH โดยก่อนที่จะนำข้อมูลเก็บลงในสแตกจะต้องมีการตรวจสอบพื้นที่ว่างในสแตกก่อน ว่ามีที่เหลือให้เก็บหรือไม่
2. การนำข้อมูลออกจากสแตก ( Deletion ) คือการนำข้อมูลที่อยู่บนสุดออกจากสแตก โดยการกระทำ เช่นนี้เราเรียกว่า POP โดยก่อนที่จะนำข้อมูลออกจากสแตก จะต้องมีการตรวจสอบว่าในสแตกมีข้อมูลเก็บ อยู่หรือไม่
3. Stack Top เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตก แต่ไม่ได้นำเอาข้อมูลนั้น
ส่วนประกอบของสแตก
การนำสแตกไปใช้งานนั้น เราจะใช้ในรูปแบบของพอยน์เตอร์ ซึ่งจะทำให้สามารถจัดการข้อมูล ที่จะเก็บในสแตกได้ง่าย โครงสร้างข้อมูลแบบสแตกจะแบ่งออกเป็น 2 ส่วน คือ
1. ตัวชี้สแตก ( Stack Pointer ) หรือ SP ซึ่งมีหน้าที่ชี้ไปยังข้อมูลที่อยู่บนสุดของสแตก ( Top stack ) หรือชี้ไปยังช่องว่างข้อมูลในสแตกที่อยู่บนข้อมูลที่บนสุด
2. สมาชิกของสแตก ( Stack Element ) เป็นข้อมูลที่จะเก็บลงไปในสแตก ซึ่งจะต้องเป็นข้อมูลชนิดเดียวกัน เช่น ข้อมูลชนิดจำนวนเต็ม
นอกจากนี้ยังต้องมีตัวกำหนดค่าสูงสุดของสแตก ( Max Stack ) ซึ่งจะเป็นตัวบอกว่าสแตกนี้สามารถเก็บ จำนวนข้อมูลได้มากที่สุดเท่าไร
เราจะเปรียบเทียบส่วนประกอบของสแตกได้ดังนี้ คือ สแตกเป็นกระป๋องเก็บลูกเทนนิส ส่วน Stack Element คือ ลูกเทนนิส ส่วนตัวชี้สแตกเป็นตัวบอกว่าขณะนี้มีลูกเทนนิสอยู่ในกระป๋องกี่ลูก ส่วน Max Stack เป็นตัวบอกว่า กระป๋องนี้เก็บลูกเทนนิสได้มากที่สุดเท่าไร

การดำเนินการเกี่ยวกับสแตก
การดำเนินการเกี่ยวกับสแตก ได้แก่
1. Create Stack
จัดสรรหน่วยความจำให้แก่ Head Nodeและส่งค่าตำแหน่งที่ชี้ไปยัง Head ของสแตกกลับมา
2. Push Stack
การเพิ่มข้อมูลลงไปในสแตก
3. Pop Stack
การนำข้อมูลบนสุดออกจากสแตก
4. Stack Top
เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตก โดยไม่มีการลบข้อมูลออกจากสแตก
5.Empty Stack
เป็นการตรวจสอบการว่างของสแตก เพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลออกจากสแตกที่เรียกว่า Stack Underflow
6. Full Stack
เป็นการตรวจสอบว่าสแตกเต็มหรือไม่ เพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลเข้าสแตกที่เรียกว่า Stack Overflow
7. Stack Count
เป็นการนับจำนวนสมาชิกในสแตก
8. Destroy Stack
เป็นการลบข้อมูลทั้งหมดที่อยู่ในสแตก
การทำงานของสแตก
สแตกมีการใช้แสดงลำดับการประมวลผลของข้อมูล เมื่อต้องการข้ามขั้นตอน บางขั้นตอนไปกระทำขั้นตอนอื่น ให้จบก่อน แล้วจึงกลับมาทำซ้ำขั้นตอนเดิม ดังตัวอย่าง
สมมติเมื่อเรากำลังประมวลผลข้อมูล A อยู่ เราต้องการข้ามไปประมวลผลข้อมูล B ให้เสร็จก่อน แล้วนำ ข้อมูลที่ได้มาใช้งานกับข้อมูล A เราจะต้องเก็บข้อมูล A ลงในสแตกก่อน (Push A) จากนั้นจึงข้ามไปทำ การประมวลผลข้อมูล B
ในขณะที่ประมวลผลข้อมูล B อยู่เราต้องข้ามไปทำข้อมูล C เพื่อนำผลที่ได้มาทำงานกับข้อมูล B เราก็จะต้อง ทำการเก็บ B ลงในสแตก (Push B) แล้วจึงจะข้ามไปทำข้อมูล C
มื่อทำข้อมูล C เสร็จเราก็จะดึงข้อมูล B ออกจากสแตก (Pop B) เพื่อทำการประมวลผล
เมื่อเราประมวลผลข้อมูล B เสร็จ เราก็จะดึงข้อมูล A ออกจากสแตก (Pop A) เพื่อทำการประมวลผล เป็นอันสิ้นสุดการประมวลผล
สแตกเป็นโครงสร้างข้อมูลชนิดหนึ่งซึ่งมีการจัดการข้อมูลแบบ LIFO ( Last In First Out ) คือ ลำดับของข้อมูลที่ถูกนำมาเก็บก่อนจะถูกนำไปใช้ทีหลัง เหมือนกับวาง จานซ้อนกัน เวลาเราจะหยิบจานไปใช้ เราต้องหยิบใบบนสุดก่อน ซึ่งเป็นจานที่ถูกวางเก็บเป็นอันดับ สุดท้าย ส่วนจานที่ถูกวางเก็บเป็นใบแรกจะนำไปใช้ได้ก็ต่อเมื่อนำจานที่วางทับมันอยู่ออกไปใช้เสียก่อน
การทำงานของสแตกจะประกอบด้วย
กระบวนการ 3 กระบวนการที่สำคัญ คือ
1. การนำข้อมูลเข้าสู่สแตก ( Insertion ) คือการนำข้อมูลเข้าไปเก็บไว้ในสแตก ซึ่งการกระทำเช่นนี้ เราเรียกว่า PUSH โดยก่อนที่จะนำข้อมูลเก็บลงในสแตกจะต้องมีการตรวจสอบพื้นที่ว่างในสแตกก่อน ว่ามีที่เหลือให้เก็บหรือไม่
2. การนำข้อมูลออกจากสแตก ( Deletion ) คือการนำข้อมูลที่อยู่บนสุดออกจากสแตก โดยการกระทำ เช่นนี้เราเรียกว่า POP โดยก่อนที่จะนำข้อมูลออกจากสแตก จะต้องมีการตรวจสอบว่าในสแตกมีข้อมูลเก็บ อยู่หรือไม่
3. Stack Top เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตก แต่ไม่ได้นำเอาข้อมูลนั้น
ส่วนประกอบของสแตก
การนำสแตกไปใช้งานนั้น เราจะใช้ในรูปแบบของพอยน์เตอร์ ซึ่งจะทำให้สามารถจัดการข้อมูล ที่จะเก็บในสแตกได้ง่าย โครงสร้างข้อมูลแบบสแตกจะแบ่งออกเป็น 2 ส่วน คือ
1. ตัวชี้สแตก ( Stack Pointer ) หรือ SP ซึ่งมีหน้าที่ชี้ไปยังข้อมูลที่อยู่บนสุดของสแตก ( Top stack ) หรือชี้ไปยังช่องว่างข้อมูลในสแตกที่อยู่บนข้อมูลที่บนสุด
2. สมาชิกของสแตก ( Stack Element ) เป็นข้อมูลที่จะเก็บลงไปในสแตก ซึ่งจะต้องเป็นข้อมูลชนิดเดียวกัน เช่น ข้อมูลชนิดจำนวนเต็ม
นอกจากนี้ยังต้องมีตัวกำหนดค่าสูงสุดของสแตก ( Max Stack ) ซึ่งจะเป็นตัวบอกว่าสแตกนี้สามารถเก็บ จำนวนข้อมูลได้มากที่สุดเท่าไร
เราจะเปรียบเทียบส่วนประกอบของสแตกได้ดังนี้ คือ สแตกเป็นกระป๋องเก็บลูกเทนนิส ส่วน Stack Element คือ ลูกเทนนิส ส่วนตัวชี้สแตกเป็นตัวบอกว่าขณะนี้มีลูกเทนนิสอยู่ในกระป๋องกี่ลูก ส่วน Max Stack เป็นตัวบอกว่า กระป๋องนี้เก็บลูกเทนนิสได้มากที่สุดเท่าไร

การดำเนินการเกี่ยวกับสแตก
การดำเนินการเกี่ยวกับสแตก ได้แก่
1. Create Stack
จัดสรรหน่วยความจำให้แก่ Head Nodeและส่งค่าตำแหน่งที่ชี้ไปยัง Head ของสแตกกลับมา
2. Push Stack
การเพิ่มข้อมูลลงไปในสแตก
3. Pop Stack
การนำข้อมูลบนสุดออกจากสแตก
4. Stack Top
เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตก โดยไม่มีการลบข้อมูลออกจากสแตก
5.Empty Stack
เป็นการตรวจสอบการว่างของสแตก เพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลออกจากสแตกที่เรียกว่า Stack Underflow
6. Full Stack
เป็นการตรวจสอบว่าสแตกเต็มหรือไม่ เพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลเข้าสแตกที่เรียกว่า Stack Overflow
7. Stack Count
เป็นการนับจำนวนสมาชิกในสแตก
8. Destroy Stack
เป็นการลบข้อมูลทั้งหมดที่อยู่ในสแตก
การทำงานของสแตก
สแตกมีการใช้แสดงลำดับการประมวลผลของข้อมูล เมื่อต้องการข้ามขั้นตอน บางขั้นตอนไปกระทำขั้นตอนอื่น ให้จบก่อน แล้วจึงกลับมาทำซ้ำขั้นตอนเดิม ดังตัวอย่าง
สมมติเมื่อเรากำลังประมวลผลข้อมูล A อยู่ เราต้องการข้ามไปประมวลผลข้อมูล B ให้เสร็จก่อน แล้วนำ ข้อมูลที่ได้มาใช้งานกับข้อมูล A เราจะต้องเก็บข้อมูล A ลงในสแตกก่อน (Push A) จากนั้นจึงข้ามไปทำ การประมวลผลข้อมูล B
ในขณะที่ประมวลผลข้อมูล B อยู่เราต้องข้ามไปทำข้อมูล C เพื่อนำผลที่ได้มาทำงานกับข้อมูล B เราก็จะต้อง ทำการเก็บ B ลงในสแตก (Push B) แล้วจึงจะข้ามไปทำข้อมูล C
มื่อทำข้อมูล C เสร็จเราก็จะดึงข้อมูล B ออกจากสแตก (Pop B) เพื่อทำการประมวลผล
เมื่อเราประมวลผลข้อมูล B เสร็จ เราก็จะดึงข้อมูล A ออกจากสแตก (Pop A) เพื่อทำการประมวลผล เป็นอันสิ้นสุดการประมวลผล
วันอาทิตย์ที่ 26 กรกฎาคม พ.ศ. 2552
ตัวอย่างการทำงานแบบ LIFOที่เห็นในชีวิตประจำวันของข้าพเจ้า
-ดินสอกดที่เวลาเราจะใส่ใส้ดินสอเราจะใส่ด้านปลายของดินสอและใส้ของดินสออันแรกจะถูกใช้เป็นอันสุดท้าย
-ผ้าขนหนูที่ใช้ในบ้านจะถูกผับเก็บในตู้และจะหยิบข้างบนใช้ก่อนซึ่งผืนที่ถูกผับก่อนจะอยู่ด้านล่างและจะถูกใช้เป็นอันสุดท้าย
-CD เปล่าที่เก็บในกล่องที่พึ่งซื้อมาและเราจะหยิบอันแรกมาใช้ก่อน ซึ่งอันแรกที่ลงไปก่อนจะถูกใช้ทีหลัง
-ขนมปังที่เรียงเป็นชั้นในถุงที่กินตอนเช้าและเราจะหยิบอันแรกมากินก่อน
-ผ้าขนหนูที่ใช้ในบ้านจะถูกผับเก็บในตู้และจะหยิบข้างบนใช้ก่อนซึ่งผืนที่ถูกผับก่อนจะอยู่ด้านล่างและจะถูกใช้เป็นอันสุดท้าย
-CD เปล่าที่เก็บในกล่องที่พึ่งซื้อมาและเราจะหยิบอันแรกมาใช้ก่อน ซึ่งอันแรกที่ลงไปก่อนจะถูกใช้ทีหลัง
-ขนมปังที่เรียงเป็นชั้นในถุงที่กินตอนเช้าและเราจะหยิบอันแรกมากินก่อน
วันอังคารที่ 21 กรกฎาคม พ.ศ. 2552
Linked List
DTS 04-15-07-09
Linked List
ลิงค์ลิสต์เป็นการจัดเก็บชุดข้อมูลเชื่อมโยงต่อเนื่องกันไปตามลำดับ ในลิสต์จะประกอบไปด้วยข้อมูลที่เรียกว่าโหนด (node)
โนดจะประกอบไปด้วย 2 ส่วนคือ
Data จะเก็บข้อมูลของอิลิเมนท์
ส่วนที่สอง คือ Link Field จะทำหน้าที่เก็บตำแหน่งของโนดต่อไปในลิสต์
ในส่วนของdataอาจจะเป็นรายการเดียวหรือเป็นเรคคอร์ดก็ได้ในส่วนของ linkจะเป็นส่วนที่เก็บตำแหน่งของโหนดถัดไปใน โหนดสุดท้ายจะเก็บคา Null ซึ่งไม่ได้ชี้ไปยังตำแหน่งใด ๆ เป็นตัวบอกการ สิ้นสุดของลิสตในลิงค์ลิสตจะมีตัวแปรสำหรับชี้ ตำแหน่งลิสต (List pointer variable)ซึ่งเป็นที่เก็บตำแหน่งเริ่มต้นของลิสต ซึ่งก็ คือโหนดแรกของลิสตนั้นเอง ถ้าลิสต์ไม่มีข้อมูล ข้อมูลในโหนดแรกของลิสตจะเป็น Null
ในส่วนของdataอาจจะเป็นรายการเดียวหรือเป็นเรคคอร์ดก็ได้ในส่วนของ linkจะเป็นส่วนที่เก็บตำแหน่งของโหนดถัดไปใน โหนดสุดท้ายจะเก็บคา Null ซึ่งไม่ได้ชี้ไปยังตำแหน่งใด ๆ เป็นตัวบอกการ สิ้นสุดของลิสตในลิงค์ลิสตจะมีตัวแปรสำหรับชี้ ตำแหน่งลิสต (List pointer variable)ซึ่งเป็นที่เก็บตำแหน่งเริ่มต้นของลิสต ซึ่งก็ คือโหนดแรกของลิสตนั้นเอง ถ้าลิสต์ไม่มีข้อมูล ข้อมูลในโหนดแรกของลิสตจะเป็น Null
โครงสร้างข้อมูลแบบลิงค์ลิสตโครงสร้างข้อมูลแบบลิงค์ลิสตจะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน ได้แก่ จำนวนโหนดในลิสต (Count)พอยเตอร์ที่ชี้ไปยัง โหนดที่เข้าถึง(Pos) และพอยเตอร์ที่ชี้ไปยังโหนดข้อูมลแรกของลิสต (Head)
2. Data Node Structure จะประกอบไปด้วยข้อมูล (Data) และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
โครงสร้างข้อมูลแบบลิงค์ลิสต์
โครงสร้างข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน
ได้แก่ จำนวนโหนดในลิสต์ (Count) พอยเตอร์ที่ชี้ไปยัง
โหนดที่เข้าถึง (Pos) และพอยเตอร์ที่ชี้ไปยังโหนดข้อมูล
แรกของลิสต์ (Head)
2. Data Node Structure จะประกอบไปด้วยข้อมูล
การลบข้อมูล
การลบข้อมูลมีหลายวิธี แต่ล่ะวิธีจะแตกต่างตามตำแหน่งของโนดที่ต้องการลบ วิธีลบโนดในแต่ล่ะตำแหน่งมีดังนี้
ตำแหน่งต้นลิสต์ ทำได้โดยให้โนดพิเศษชี้ไปโนดที่2ของลิสต์
ตำแหน่งท้ายลิสต์ การลบโนด ทำได้โดยให้ตัวชี้ของโนดรองสุดท้ายมีค่าเป็นNULL
ตำแหน่งท้ายลิสต์ กำหนดให้ตัวชี้ prev ชี้ที่โนดก่อนหน้าโนดที่ต้องการลบ และตัวชี้ p ชี้ที่โนดที่ต้องการลบ
ในการลบโนดควรตรวจสอบก่อนว่าในลิสต์นั้นมีสมาชิกกี่จำนวน ถ้าเหลือเพียงจำนวนเดียวก็หมายความว่า หลังจากลบโนดทิ้งแล้วจะกลายเป็นลิสต์ว่างไม่จำเป็นต้องเชื่อมโยงโนดใหม่
Linked List
ลิงค์ลิสต์เป็นการจัดเก็บชุดข้อมูลเชื่อมโยงต่อเนื่องกันไปตามลำดับ ในลิสต์จะประกอบไปด้วยข้อมูลที่เรียกว่าโหนด (node)
โนดจะประกอบไปด้วย 2 ส่วนคือ
Data จะเก็บข้อมูลของอิลิเมนท์
ส่วนที่สอง คือ Link Field จะทำหน้าที่เก็บตำแหน่งของโนดต่อไปในลิสต์
ในส่วนของdataอาจจะเป็นรายการเดียวหรือเป็นเรคคอร์ดก็ได้ในส่วนของ linkจะเป็นส่วนที่เก็บตำแหน่งของโหนดถัดไปใน โหนดสุดท้ายจะเก็บคา Null ซึ่งไม่ได้ชี้ไปยังตำแหน่งใด ๆ เป็นตัวบอกการ สิ้นสุดของลิสตในลิงค์ลิสตจะมีตัวแปรสำหรับชี้ ตำแหน่งลิสต (List pointer variable)ซึ่งเป็นที่เก็บตำแหน่งเริ่มต้นของลิสต ซึ่งก็ คือโหนดแรกของลิสตนั้นเอง ถ้าลิสต์ไม่มีข้อมูล ข้อมูลในโหนดแรกของลิสตจะเป็น Null
ในส่วนของdataอาจจะเป็นรายการเดียวหรือเป็นเรคคอร์ดก็ได้ในส่วนของ linkจะเป็นส่วนที่เก็บตำแหน่งของโหนดถัดไปใน โหนดสุดท้ายจะเก็บคา Null ซึ่งไม่ได้ชี้ไปยังตำแหน่งใด ๆ เป็นตัวบอกการ สิ้นสุดของลิสตในลิงค์ลิสตจะมีตัวแปรสำหรับชี้ ตำแหน่งลิสต (List pointer variable)ซึ่งเป็นที่เก็บตำแหน่งเริ่มต้นของลิสต ซึ่งก็ คือโหนดแรกของลิสตนั้นเอง ถ้าลิสต์ไม่มีข้อมูล ข้อมูลในโหนดแรกของลิสตจะเป็น Null
โครงสร้างข้อมูลแบบลิงค์ลิสตโครงสร้างข้อมูลแบบลิงค์ลิสตจะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน ได้แก่ จำนวนโหนดในลิสต (Count)พอยเตอร์ที่ชี้ไปยัง โหนดที่เข้าถึง(Pos) และพอยเตอร์ที่ชี้ไปยังโหนดข้อูมลแรกของลิสต (Head)
2. Data Node Structure จะประกอบไปด้วยข้อมูล (Data) และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
โครงสร้างข้อมูลแบบลิงค์ลิสต์
โครงสร้างข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน
ได้แก่ จำนวนโหนดในลิสต์ (Count) พอยเตอร์ที่ชี้ไปยัง
โหนดที่เข้าถึง (Pos) และพอยเตอร์ที่ชี้ไปยังโหนดข้อมูล
แรกของลิสต์ (Head)
2. Data Node Structure จะประกอบไปด้วยข้อมูล
การลบข้อมูล
การลบข้อมูลมีหลายวิธี แต่ล่ะวิธีจะแตกต่างตามตำแหน่งของโนดที่ต้องการลบ วิธีลบโนดในแต่ล่ะตำแหน่งมีดังนี้
ตำแหน่งต้นลิสต์ ทำได้โดยให้โนดพิเศษชี้ไปโนดที่2ของลิสต์
ตำแหน่งท้ายลิสต์ การลบโนด ทำได้โดยให้ตัวชี้ของโนดรองสุดท้ายมีค่าเป็นNULL
ตำแหน่งท้ายลิสต์ กำหนดให้ตัวชี้ prev ชี้ที่โนดก่อนหน้าโนดที่ต้องการลบ และตัวชี้ p ชี้ที่โนดที่ต้องการลบ
ในการลบโนดควรตรวจสอบก่อนว่าในลิสต์นั้นมีสมาชิกกี่จำนวน ถ้าเหลือเพียงจำนวนเดียวก็หมายความว่า หลังจากลบโนดทิ้งแล้วจะกลายเป็นลิสต์ว่างไม่จำเป็นต้องเชื่อมโยงโนดใหม่
แบบฝึกหัดบทที่ 2
1. ให้นักศึกษากำหนดค่าของ Array 1 มิติ และ Array 2 มิติ
ตอบ
อาเรย์ คือชุดของตัวแปร ที่มีชื่อตัวแปรและชนิดตัวแปรเดียวกัน มักใช้กับตัวแปรชนิดเดียวกันหลายๆ ตัว ที่มีการทำงานเหมือนกัน เช่นคะแนนนักศึกษา 40 คน ชื่อทุกกระบวนวิชาที่เปิดสอนภายในภาควิชา (เช่นอาจมี 40 กระบวนวิชา ก็จะมีข้อมูล 40 ชื่อ) เป็นต้น
รูปแบบการประกาศอาเรย์
ชนิดข้อมูล ชื่อตัวแปร [ขนาดข้อมูล];
ตัวอย่าง ต้องการเก็บข้อมูลคะแนนสอบของนักศึกษา 10 คนไว้ในตัวแปร array จะต้องการประกาศตัวแปรอาเรย์ ดังนี้
float score[10];
อาเรย์ 2 มิติ
ข้อมูลในอาเรย์ 2 มิติ จะเป็นลักษณะของตาราง
ซึ่งมีแถวและคอลัมน์
แถว (row)
คอลัมน์ (column)
score[row][column] เช่น score[0][4]
_____________________________
2. ให้นักศึกษาหาค่าของ A[2], A[6] จากค่า A={2,8,16,24,9,7,3,8}
ตอบ A[2] คือ 16 A[6] คือ 3
_____________________________
3. จากค่าของ int a[2][3] = {{6,5,4},{3,2,1}};
ให้นักศึกษา หาค่าของ a[1][0] และ a[0][2]
char a[2][3];
col1 col2 col3
row1 a[0][0] =6 a[0][1] =5 a[0][2] =4
row 2 a[1][0] =3 a[1][1] =2 a[1][2] =1
ตอบ ค่าของ a[1][0] = 3
a[0][2] = 4
______________________________
4. ให้นักศึกษากำหนด Structure ที่มีค่าของข้อมูลจากน้อย 6 Records
ตอบ struct student
#include<stdio.h>
struct student
{
char name[30];
char lastname[40];
int age;
char sex;
int day;
int month;
int year;
char address[20];
}data;
void main()
{
______________________________
5. ให้นักศึกษาบอกความแตกต่างของการกำหนดตัวชนิด Array กับ
ตัวแปร Pointer ในสภาพของการกำหนดที่อยู่ของข้อมูล
ตอบ
array หมายถึง ตัวแปรชุดที่ใช้เก็บตัวแปรชนิดเดียวกันไว้ด้วยกัน เช่น เก็บ ข้อมูล char ไว้กับ char เก็บ int ไว้กับ int ไม่สามารถเก็บข้อมูลต่างชนิดกันได้ เช่น char กับ int เรียก array อีกอย่างว่าหน่วยความจำแบ่งเป็นช่อง การกำหนดสมาชิกชิกของ array จะเขียนภายในเครื่องหมาย [ ]
pointer หมายถึง ตัวเก็บตำแหน่งที่อยู่ของหน่วยความจำ (Address) หรือเรียกว่า ตัวชี้ ตำแหน่งที่อยู่ สัญลักษณ์ของ pointer จะแทนด้วยเครื่องหมาย *
array m3[ ] จะเก็บข้อมูลอยู่ใน array มีพื้นที่เก็บข้อมูลเป็นของตัวแปรนี้และชื่อ m3 จะมี ค่า address คงที่ไม่สามารถเปลี่ยนค่าได้ใช้ m3 + 1 ได้ แต่ใช้ m3++ ไม่ได้
pointer *m3 จะชี้ไปที่ที่เก็บข้อมูล จากตัวอย่างข้างต้นจะมีพื้นที่ส่วนหนึ่งที่ใช้ในการเก็บ string ชุดนี้ไว้แล้ว m3 จะชี้ไปที่ address ของพื้นที่นั้น ๆ เราสามารถที่จะทำการเปลี่ยนค่าของ m3 ได้โดยใช้ m3++
ตอบ
อาเรย์ คือชุดของตัวแปร ที่มีชื่อตัวแปรและชนิดตัวแปรเดียวกัน มักใช้กับตัวแปรชนิดเดียวกันหลายๆ ตัว ที่มีการทำงานเหมือนกัน เช่นคะแนนนักศึกษา 40 คน ชื่อทุกกระบวนวิชาที่เปิดสอนภายในภาควิชา (เช่นอาจมี 40 กระบวนวิชา ก็จะมีข้อมูล 40 ชื่อ) เป็นต้น
รูปแบบการประกาศอาเรย์
ชนิดข้อมูล ชื่อตัวแปร [ขนาดข้อมูล];
ตัวอย่าง ต้องการเก็บข้อมูลคะแนนสอบของนักศึกษา 10 คนไว้ในตัวแปร array จะต้องการประกาศตัวแปรอาเรย์ ดังนี้
float score[10];
อาเรย์ 2 มิติ
ข้อมูลในอาเรย์ 2 มิติ จะเป็นลักษณะของตาราง
ซึ่งมีแถวและคอลัมน์
แถว (row)
คอลัมน์ (column)
score[row][column] เช่น score[0][4]
_____________________________
2. ให้นักศึกษาหาค่าของ A[2], A[6] จากค่า A={2,8,16,24,9,7,3,8}
ตอบ A[2] คือ 16 A[6] คือ 3
_____________________________
3. จากค่าของ int a[2][3] = {{6,5,4},{3,2,1}};
ให้นักศึกษา หาค่าของ a[1][0] และ a[0][2]
char a[2][3];
col1 col2 col3
row1 a[0][0] =6 a[0][1] =5 a[0][2] =4
row 2 a[1][0] =3 a[1][1] =2 a[1][2] =1
ตอบ ค่าของ a[1][0] = 3
a[0][2] = 4
______________________________
4. ให้นักศึกษากำหนด Structure ที่มีค่าของข้อมูลจากน้อย 6 Records
ตอบ struct student
#include<stdio.h>
struct student
{
char name[30];
char lastname[40];
int age;
char sex;
int day;
int month;
int year;
char address[20];
}data;
void main()
{
______________________________
5. ให้นักศึกษาบอกความแตกต่างของการกำหนดตัวชนิด Array กับ
ตัวแปร Pointer ในสภาพของการกำหนดที่อยู่ของข้อมูล
ตอบ
array หมายถึง ตัวแปรชุดที่ใช้เก็บตัวแปรชนิดเดียวกันไว้ด้วยกัน เช่น เก็บ ข้อมูล char ไว้กับ char เก็บ int ไว้กับ int ไม่สามารถเก็บข้อมูลต่างชนิดกันได้ เช่น char กับ int เรียก array อีกอย่างว่าหน่วยความจำแบ่งเป็นช่อง การกำหนดสมาชิกชิกของ array จะเขียนภายในเครื่องหมาย [ ]
pointer หมายถึง ตัวเก็บตำแหน่งที่อยู่ของหน่วยความจำ (Address) หรือเรียกว่า ตัวชี้ ตำแหน่งที่อยู่ สัญลักษณ์ของ pointer จะแทนด้วยเครื่องหมาย *
array m3[ ] จะเก็บข้อมูลอยู่ใน array มีพื้นที่เก็บข้อมูลเป็นของตัวแปรนี้และชื่อ m3 จะมี ค่า address คงที่ไม่สามารถเปลี่ยนค่าได้ใช้ m3 + 1 ได้ แต่ใช้ m3++ ไม่ได้
pointer *m3 จะชี้ไปที่ที่เก็บข้อมูล จากตัวอย่างข้างต้นจะมีพื้นที่ส่วนหนึ่งที่ใช้ในการเก็บ string ชุดนี้ไว้แล้ว m3 จะชี้ไปที่ address ของพื้นที่นั้น ๆ เราสามารถที่จะทำการเปลี่ยนค่าของ m3 ได้โดยใช้ m3++
วันจันทร์ที่ 13 กรกฎาคม พ.ศ. 2552
สรุปการเรียน Set and String
DTS 03-01-07-09
Pointer คือ ตัวแปรชนิดหนึ่งที่อ้างอิงไปยังตำแหน่งของหน่วยความจำ (Address) เป็นการใช้ตัวชี้จะทำให้โปรแกรมรวดเร็วและ มีขนาดเล็ก
การประกาศตัวแปรPointer
type *variable_name ;
หรือ type *variable_name1, *variable_name2,... ,*variable_nameN ;
โดย type คือ ชนิดของตัวแปร เช่น int ,float ,char ฯลฯ โดยต้องเป็นชนิดเดียวกับของตัวแปรหรือข้อมูลที่พอยน์เตอร์นั้นเก็บตำแหน่งที่อยู่
* เป็นเครื่องหมายที่ระบุว่าเป็นตัวแปรพอยน์เตอร์
variable_name1, variable_name2,..., variable_nameN ชื่อตัวแปรพอยน์ตัวที่ 1 ถึง ตัวสุดท้ายที่ประกาศในการประกาศครั้งนี้
โครงสร้างข้อมูลแบบเซ็ต
เป็นโครงสร้างข้อมูลแต่ละตัวไม่มีความสัมพันธ์กันเลย ในภาษาซีจะไม่มีประเภทข้อมูลแบบเซ็ตเหมือนกับภาษาปาสคา แต่สามารถใช้หลักในการดำเนินงานแบบเซ็ตได้
โครงสร้างข้อมูลแบบสตริง
สตริง เป็นข้อมูลประกอบไปด้วย ตัวอักษร ตัวเลขหรือเครื่องหมาย ที่เรียงต่อๆกันไป รวมทั้งช่องว่างด้วยสตริงกับอะเรย์ สตริงคือ อะเรย์ของอักขระ
เช่น Char name[15]
อาจจะเป็นอะเรย์ขนาด 15 ช่องอักขระ หรือเป็นสตริงขนาด 15 อักขระก็ได้ โดยจุดสิ้นสุดขอบ สตริง จะจบด้วย \0 หรือ null character
เช่น char b[] = {'S' ,'A ','W', 'A' ,'S ','D' ,'E' ,'E' ,'\0'};
หรือ char b[] = "SAWASDEE";
การกำหนดตัวแปรสตริง อาศัยหลักการของอะเรย์ เพราะสตริงคืออะเรย์ของอักขระที่เปิดท้ายด้วย (\0) และมีฟังก์ชันพิเศษสำหรับการทำงานของสตริงโดยเฉพาะ
Pointer คือ ตัวแปรชนิดหนึ่งที่อ้างอิงไปยังตำแหน่งของหน่วยความจำ (Address) เป็นการใช้ตัวชี้จะทำให้โปรแกรมรวดเร็วและ มีขนาดเล็ก
การประกาศตัวแปรPointer
type *variable_name ;
หรือ type *variable_name1, *variable_name2,... ,*variable_nameN ;
โดย type คือ ชนิดของตัวแปร เช่น int ,float ,char ฯลฯ โดยต้องเป็นชนิดเดียวกับของตัวแปรหรือข้อมูลที่พอยน์เตอร์นั้นเก็บตำแหน่งที่อยู่
* เป็นเครื่องหมายที่ระบุว่าเป็นตัวแปรพอยน์เตอร์
variable_name1, variable_name2,..., variable_nameN ชื่อตัวแปรพอยน์ตัวที่ 1 ถึง ตัวสุดท้ายที่ประกาศในการประกาศครั้งนี้
โครงสร้างข้อมูลแบบเซ็ต
เป็นโครงสร้างข้อมูลแต่ละตัวไม่มีความสัมพันธ์กันเลย ในภาษาซีจะไม่มีประเภทข้อมูลแบบเซ็ตเหมือนกับภาษาปาสคา แต่สามารถใช้หลักในการดำเนินงานแบบเซ็ตได้
โครงสร้างข้อมูลแบบสตริง
สตริง เป็นข้อมูลประกอบไปด้วย ตัวอักษร ตัวเลขหรือเครื่องหมาย ที่เรียงต่อๆกันไป รวมทั้งช่องว่างด้วยสตริงกับอะเรย์ สตริงคือ อะเรย์ของอักขระ
เช่น Char name[15]
อาจจะเป็นอะเรย์ขนาด 15 ช่องอักขระ หรือเป็นสตริงขนาด 15 อักขระก็ได้ โดยจุดสิ้นสุดขอบ สตริง จะจบด้วย \0 หรือ null character
เช่น char b[] = {'S' ,'A ','W', 'A' ,'S ','D' ,'E' ,'E' ,'\0'};
หรือ char b[] = "SAWASDEE";
การกำหนดตัวแปรสตริง อาศัยหลักการของอะเรย์ เพราะสตริงคืออะเรย์ของอักขระที่เปิดท้ายด้วย (\0) และมีฟังก์ชันพิเศษสำหรับการทำงานของสตริงโดยเฉพาะ
วันพุธที่ 1 กรกฎาคม พ.ศ. 2552
DTS02-24/06/2009
#include<stdio.h>
struct student
{
char name[30];
char lastname[40];
int age;
char sex;
int day;
int month;
int year;
char address[20];
}data;
void main()
{
printf("studen data\n");
printf("name:");
scanf("%s",&data.name);
printf("lastname:");
scanf("%s",&data.lastname);
printf("age:");
scanf("%d",&data.age);
printf("sex:");
scanf("%s",&data.sex);
printf("date of birth (d/m/y):");
scanf("%d/%d/%d",&data.day,&data.month,&data.year);
printf("address:");
scanf("%s",&data.address);
{
printf("\n\n\nDisplay Data of student\n");
printf("Name : %s\n",data.name);
printf("Lastname : %s\n",data.lastname);
printf("Age : %d\n",data.age);
printf("sex : %s\n",data.lastname);
printf("birthday : %d/%d/%d\n",data.day,data.month,data.year);
printf("address : %s\n",data.address);
}
}
struct student
{
char name[30];
char lastname[40];
int age;
char sex;
int day;
int month;
int year;
char address[20];
}data;
void main()
{
printf("studen data\n");
printf("name:");
scanf("%s",&data.name);
printf("lastname:");
scanf("%s",&data.lastname);
printf("age:");
scanf("%d",&data.age);
printf("sex:");
scanf("%s",&data.sex);
printf("date of birth (d/m/y):");
scanf("%d/%d/%d",&data.day,&data.month,&data.year);
printf("address:");
scanf("%s",&data.address);
{
printf("\n\n\nDisplay Data of student\n");
printf("Name : %s\n",data.name);
printf("Lastname : %s\n",data.lastname);
printf("Age : %d\n",data.age);
printf("sex : %s\n",data.lastname);
printf("birthday : %d/%d/%d\n",data.day,data.month,data.year);
printf("address : %s\n",data.address);
}
}
วันพุธที่ 24 มิถุนายน พ.ศ. 2552
ประวัติส่วนตัว

นางสาว ฉัตรธิดา วงศ์จอม
MISS CHATTIDA WONGJOM
รหัสนักศึกษา 50152792061
หลักสูตร บริหารธุรกิจ(คอมพิวเตอร์ธูรกิจ)คณะวิทยาการจัดการ
มหาวิทยาลัยราชภัฏสวนดุสิต
e-mail address:u50152792061
MISS CHATTIDA WONGJOM
รหัสนักศึกษา 50152792061
หลักสูตร บริหารธุรกิจ(คอมพิวเตอร์ธูรกิจ)คณะวิทยาการจัดการ
มหาวิทยาลัยราชภัฏสวนดุสิต
e-mail address:u50152792061
DTS 01-24-06-255
สรุปการเรียน Array and record
อะเรย์จะต้องมีการกำหนดชื่ออะเรย์พร้อม supscript
การกำหนดขอบเขตของอะเรย์มีได้มากกว่า 1 จำนวน
supscript จะเป็นตัวบอกมิติของอะเรย์นั้นและอะเรย์ที่มี
supscript มากกว่า 1 ตัวขึ้นไปจะเรียกว่า อะเรย์หลายมิติ
การจัดเก็บอะเรย์ในหน่วยความจำจะพิจารณาตามประเภทของอะเรย์ในมิติต่างๆ
การส่งค่าอะเรย์ให้ฟังก์ชันทำได้โดยการกำหนดค่า array element เป็น
พารามิเตอร์ส่งค่าให้กับฟังก์ชันทำได้โดยการอ้างถึงชื่ออะเรย์พร้อมระบุ
supscript
ถ้าไม่ได้ระบุอาร์กิวเมนต์ จะมีการสร้างอาร์เรย์ที่มีความยาวเท่ากับศูนย์ชนิดข้อมูล(Data type)ของตัวแปรคือเซตของค่าที่เป็นไปได้ของตัวแปรนั้น ซึ่งจะกำหนดเซตของ opertions ที่จะทำกับตัวแปรนั้นได้ด้วย ภาษาซีไม่ยอมให้ใช้งานตัวแปรก่อนประกาศค่า เนื่องจากการประกาศตัวแปรต้องบอกชนิดของข้อมูลด้วย จะทำให้ชุดคำสั่งทราบขนาดการจองที่ในหน่วยความจำหลัก ภาษาซีแบ่งประเภทข้อมูลออกเป็นชนิดต่างๆ เพื่อให้เหมาะสมกับการนำไปใช้งาน ข้อมูลแต่ละชนิดจะใช้ขนาดพื้นที่หน่วยความจำต่างกัน ตลอดจนช่วงของค่าข้อมูลที่จัดเก็บได้ก็แต่ต่างกันด้วย
ตัวแปร คือ ชื่อพื้นที่หน่วยความจำที่ตั้งขึ้นมาเพื่อใช้จัดเก็บข้อมูล การอ้างอิงผ่านชื่อตัวแปร จะสะดวกกว่าการใช้ตำแหน่งที่แท้จริง การตั้งชื่อตัวแปรจะเป็นไปตามข้อกำหนดของแต่ละภาษา
การประกาศตัวแปรของภาษาซี ใช้รูปแบบดังนี้
<ชนิดข้อมูล><ชื่อตัวแปร>[=ค่าเริ่มต้น][,ตัวแปร[=ค่าเริ่มต้น]];
ตัวอย่าง การประกาศและให้ค่าตัวแปรของภาษาซี
char msg []="your welcome";
int i, x=5;
float price, y=9.12;
การกำหนดขอบเขตของอะเรย์มีได้มากกว่า 1 จำนวน
supscript จะเป็นตัวบอกมิติของอะเรย์นั้นและอะเรย์ที่มี
supscript มากกว่า 1 ตัวขึ้นไปจะเรียกว่า อะเรย์หลายมิติ
การจัดเก็บอะเรย์ในหน่วยความจำจะพิจารณาตามประเภทของอะเรย์ในมิติต่างๆ
การส่งค่าอะเรย์ให้ฟังก์ชันทำได้โดยการกำหนดค่า array element เป็น
พารามิเตอร์ส่งค่าให้กับฟังก์ชันทำได้โดยการอ้างถึงชื่ออะเรย์พร้อมระบุ
supscript
ถ้าไม่ได้ระบุอาร์กิวเมนต์ จะมีการสร้างอาร์เรย์ที่มีความยาวเท่ากับศูนย์ชนิดข้อมูล(Data type)ของตัวแปรคือเซตของค่าที่เป็นไปได้ของตัวแปรนั้น ซึ่งจะกำหนดเซตของ opertions ที่จะทำกับตัวแปรนั้นได้ด้วย ภาษาซีไม่ยอมให้ใช้งานตัวแปรก่อนประกาศค่า เนื่องจากการประกาศตัวแปรต้องบอกชนิดของข้อมูลด้วย จะทำให้ชุดคำสั่งทราบขนาดการจองที่ในหน่วยความจำหลัก ภาษาซีแบ่งประเภทข้อมูลออกเป็นชนิดต่างๆ เพื่อให้เหมาะสมกับการนำไปใช้งาน ข้อมูลแต่ละชนิดจะใช้ขนาดพื้นที่หน่วยความจำต่างกัน ตลอดจนช่วงของค่าข้อมูลที่จัดเก็บได้ก็แต่ต่างกันด้วย
ตัวแปร คือ ชื่อพื้นที่หน่วยความจำที่ตั้งขึ้นมาเพื่อใช้จัดเก็บข้อมูล การอ้างอิงผ่านชื่อตัวแปร จะสะดวกกว่าการใช้ตำแหน่งที่แท้จริง การตั้งชื่อตัวแปรจะเป็นไปตามข้อกำหนดของแต่ละภาษา
การประกาศตัวแปรของภาษาซี ใช้รูปแบบดังนี้
<ชนิดข้อมูล><ชื่อตัวแปร>[=ค่าเริ่มต้น][,ตัวแปร[=ค่าเริ่มต้น]];
ตัวอย่าง การประกาศและให้ค่าตัวแปรของภาษาซี
char msg []="your welcome";
int i, x=5;
float price, y=9.12;
สมัครสมาชิก:
บทความ (Atom)
